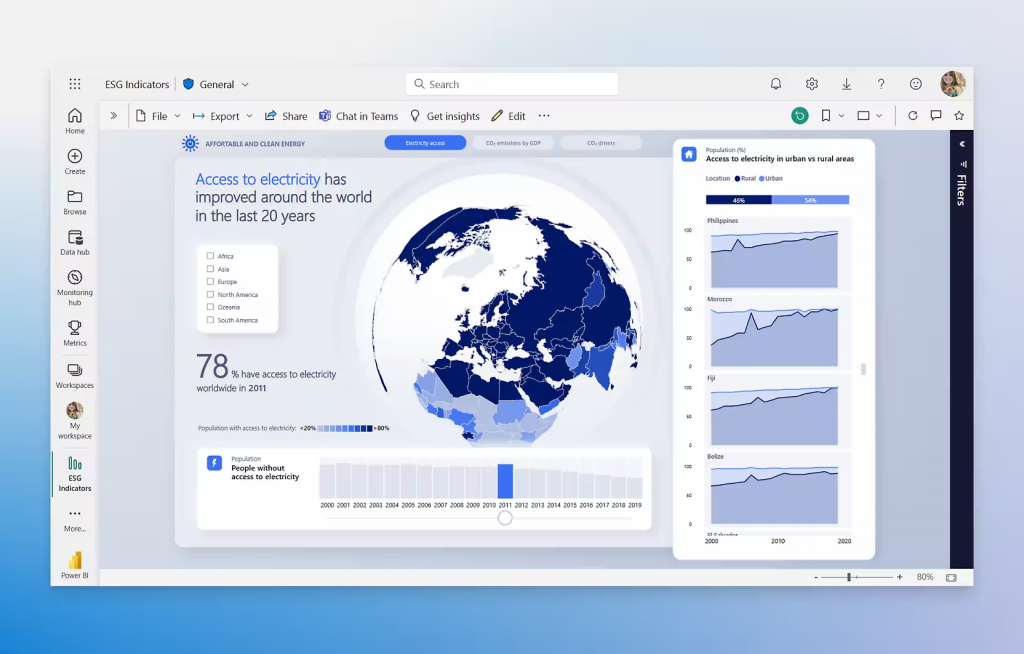
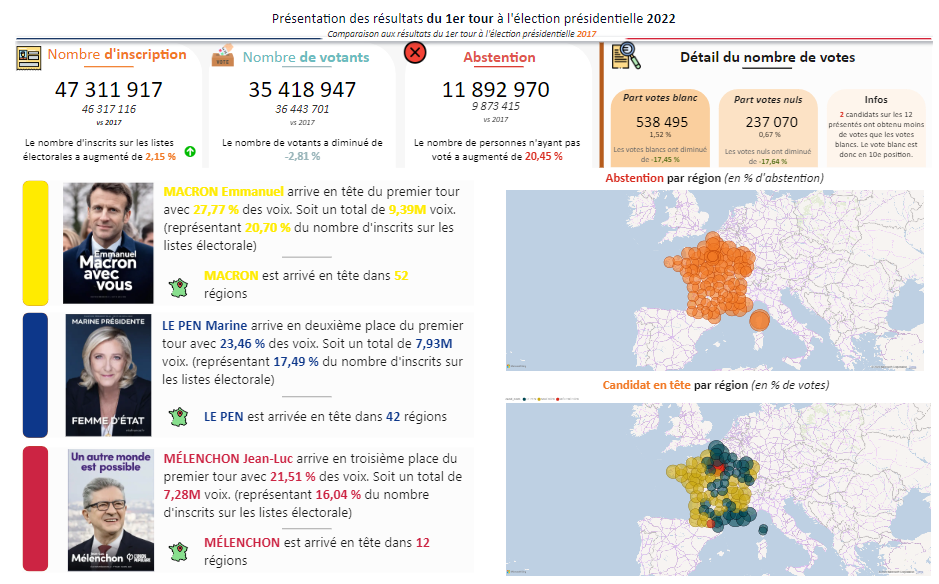
À moins que vous ne viviez dans une grotte depuis ces cinq dernières années, Power BI est devenu la référence en matière d’outil de visualisation de données. On parle souvent d’outils de DataViz.
Leader depuis des années sur le Gartner, Power BI se démarque par son intégration native dans l’écosystème Microsoft Office 365 et par sa courbe d’apprentissage très rapide.
Mais attention, il ne faut pas tomber dans le panneau. Même si l’outil se veut accessible et très adapté pour des personnes novices, il n’en reste pas moins très complet, voire même très compliqué à maîtriser dès lors qu’il faut aller plus loin !
La promesse que « même votre belle-mère » pourrait faire du Power BI est vraie, dans une certaine limite.
« BI » de Power BI
Avant de parler de notre outil qui fait des feux d’artifice dans tous les sens, avant de parler de rapport sexy et ergonomique, il est PRIMORDIAL de comprendre dans quel contexte il s’inscrit : la Business Intelligence (et la Data au global).
Power BI est un outil de restitution, qui permet de visualiser des données provenant de sources variées comme du Excel, vos bases de données métiers, votre ERP, votre CRM ou toutes autres solutions stockant de la donnée.
Dans un monde idéal, Power BI ne doit pas interroger les données de vos bases de production en direct. (Ne serait-ce que pour des questions de performances, mais on y reviendra).
Power BI doit arriver au bout d’une chaîne d’ingestion, traitement et stockage de la donnée.
L’objectif ? S’appuyer sur des données travaillées, nettoyées, fiables et prêtes à la consommation.
La magie derrière le rideau !
Ce qui rend Power BI si magique, c’est sa capacité à intégrer des sources de données aussi variées que des feuilles de calcul Excel, des bases de données, des flux en direct et même des réseaux sociaux, pour n’en citer que quelques-unes. Il les mélange toutes dans un chaudron pour en sortir des visualisations interactives et des rapports qui racontent l’histoire cachée derrière vos données.
En bref !
Je pense que pour un premier article sur l’outil, ça sera suffisant. Vous connaissez pour la plupart déjà très bien Power BI.
Ce qu’il faut retenir :
Un outil dédié à la Data Visualisation
Très puissant dans les transformations grâce à Power Query
Capacité native à faire du mobile/tablette
Une solution SaaS pour le partage (Power BI Service)
S’intègre nativement avec la suite office 365
Le prochain article traitera de ces composants en détails pour bien identifier quelle fonctionnalité utiliser.
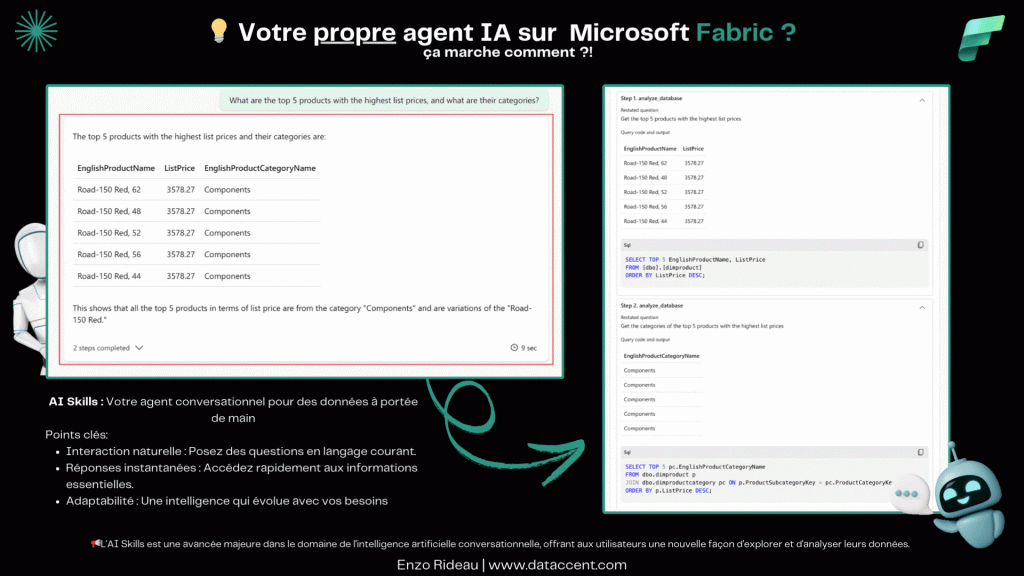
La brique qui manquait à l’IA pour (enfin) comprendre votre modèle
Depuis l’arrivée du Copilot et des agents conversationnels dans l’écosystème Microsoft Fabric, une promesse forte est posée sur la table : permettre aux utilisateurs de dialoguer naturellement avec leurs données. Mais dans les faits, cette promesse s’est souvent heurtée à une réalité bien connue des professionnels de la donnée : le contexte métier, les règles implicites, et la complexité des modèles ne se devinent pas.
Et c’est précisément là qu’intervient la nouveauté Data Source Instructions.
Le problème : une IA sans contexte reste une IA bancale
Lorsqu’un utilisateur interroge un agent dans Fabric avec une simple question en langage naturel, celui-ci doit décider quelle table interroger, comment construire la requête, quelles jointures appliquer, quels filtres considérer… Bref, il fait des hypothèses.
Et sans guide clair, ces hypothèses sont parfois complètement à côté de la plaque.
Jusqu’à maintenant, la configuration de ces agents se faisait principalement à un niveau global. On pouvait donner quelques grandes orientations, mais cela restait souvent trop générique pour gérer des jeux de données un peu riches, ou des logiques métier fines.
Ce que Microsoft ajoute avec les Data Source Instructions
Avec cette mise à jour, chaque source de données connectée à un agent peut désormais recevoir ses propres instructions spécifiques.
On parle ici de la possibilité de documenter, orienter, cadrer le comportement de l’agent au niveau de chaque source, et non plus uniquement de manière globale.
En pratique, cela permet de :
Prioriser certaines tables selon les cas d’usage.
Définir des jointures par défaut à appliquer systématiquement.
Expliquer la signification métier de certaines colonnes (codes région, statut, etc.).
Ajouter des filtres implicites qui reflètent les règles business (ne prendre en compte que les données actives, par exemple).
Uniformiser l’interprétation des requêtes même lorsque la terminologie est floue côté utilisateur.
Ce que ça change vraiment
Ce n’est pas une simple option en plus dans la configuration de vos agents. C’est un changement de paradigme.
Là où auparavant l’IA tentait de « faire de son mieux », elle peut désormais travailler avec des consignes explicites, proches d’un cahier des charges, source par source.
C’est exactement comme si vous ajoutiez une couche de documentation technique et métier que l’agent peut lire, comprendre et appliquer à chaque requête.
Et dans des contextes où :
plusieurs sources contiennent des données similaires,
des règles métiers évoluent dans le temps,
certaines jointures sont obligatoires pour éviter les erreurs d’analyse,
… cette fonctionnalité est tout simplement vitale.
Exemples concrets d’instructions
Quelques exemples d’instructions que vous pouvez maintenant définir :
« Lorsque la question porte sur les ventes passées, utilisez la table Orders et appliquez un filtre sur OrderDate. »
« Joindre systématiquement Sales et Products via ProductID avant d’agréger des montants. »
« La colonne State contient des abréviations : utilisez ‘CA’, ‘NY’ et non ‘California’ ou ‘New York’. »
« Ne jamais afficher les lignes dont le statut est ‘Archivé’. »
Mon retour terrain : un vrai pas en avant, mais pas une baguette magique
Cette nouveauté est une excellente nouvelle pour les équipes data, mais elle demande de la rigueur. Voici quelques points d’attention si vous voulez en tirer parti :
1. Il faut investir du temps. Écrire des instructions claires, utiles et robustes, ça ne se fait pas en 5 minutes. Il faut connaître le modèle, parler avec les métiers, et tester.
2. L’instruction ne remplace pas la modélisation. Si vos jeux de données sont mal conçus, si vos jointures sont incohérentes, ou si vos colonnes sont mal typées, aucune instruction ne sauvera l’agent. Ce n’est pas une rustine, c’est un amplificateur de qualité.
3. Attention à la maintenance. Plus vous ajoutez d’instructions, plus vous devrez les maintenir. Si vos règles métier changent ou si votre modèle évolue, vous devrez faire le ménage pour ne pas introduire de décalage entre le discours de l’IA et la réalité des données.
Pourquoi c’est une avancée stratégique
Si Microsoft veut que les agents conversationnels deviennent des copilotes métier réellement efficaces, il fallait passer par là.
Le discours « demandez ce que vous voulez, l’IA se débrouillera » a montré ses limites. Il faut outiller cette IA avec du contexte, du sens, de la structure.
Et avec cette fonctionnalité, on se rapproche d’un équilibre intéressant : une IA guidée, mais toujours accessible, qui ne demande pas d’écrire du code, mais qui peut enfin s’appuyer sur des règles solides pour éviter les réponses absurdes.
Ce que je recommande
Commencez petit.
Prenez un agent, une ou deux sources bien connues, et testez l’impact des instructions. Formulez quelques règles simples, testez des requêtes avec et sans instruction, et mesurez la différence. Vous verrez très vite l’effet.
Ensuite, industrialisez : définissez des conventions pour écrire ces instructions, centralisez leur gestion, et intégrez ce travail dans vos processus de data governance.
Cette nouveauté ne fera pas le buzz comme un Copilot qui génère un rapport en un clic. Et pourtant, elle a beaucoup plus d’impact réel.
Elle permet à vos agents de ne plus juste “réagir”, mais de comprendre votre univers métier.
Avec les Data Source Instructions, Microsoft Fabric franchit une étape essentielle : celle d’une IA plus intelligente non pas parce qu’elle devine mieux, mais parce qu’on lui a enfin expliqué les règles du jeu.
Microsoft Copilot pour Power BI désigne un assistant intelligent intégré à Power BI (Desktop et Service) qui exploite des modèles de langage avancés (Large Language Models d’OpenAI) pour aider les utilisateurs à analyser et créer des rapports plus efficacement. Dans le contexte de Power BI, Copilot comprend le langage naturel de l’utilisateur et peut générer des réponses ou des contenus en fonction des demandes formulées.
Que ce soit pour créer une page de rapport, écrire une formule DAX ou résumer des données, Copilot exécute la requête et propose un résultat que l’utilisateur peut ensuite ajuster selon ses besoins. L’objectif est de simplifier des tâches complexes et de rendre la business intelligence plus accessible : un utilisateur peut décrire ce qu’il veut obtenir et l’IA se charge de le réaliser, transformant Power BI en un véritable assistant analytique intelligent.
Dans cet article de blog, nous passerons en revue les capacités actuelles de Copilot dans Power BI (Desktop et Service) au 18 juin 2025, y compris les fonctionnalités en préversion, et ce qu’elles permettent concrètement. Pour chaque fonctionnalité, nous décrirons son fonctionnement, un cas d’usage concret pour un contrôleur de gestion, les avantages que l’on peut en attendre, ainsi que les limites ou considérations à connaître (qu’elles soient techniques, linguistiques ou organisationnelles). Nous aborderons ensuite les perspectives d’évolution de Copilot selon Microsoft et la communauté.
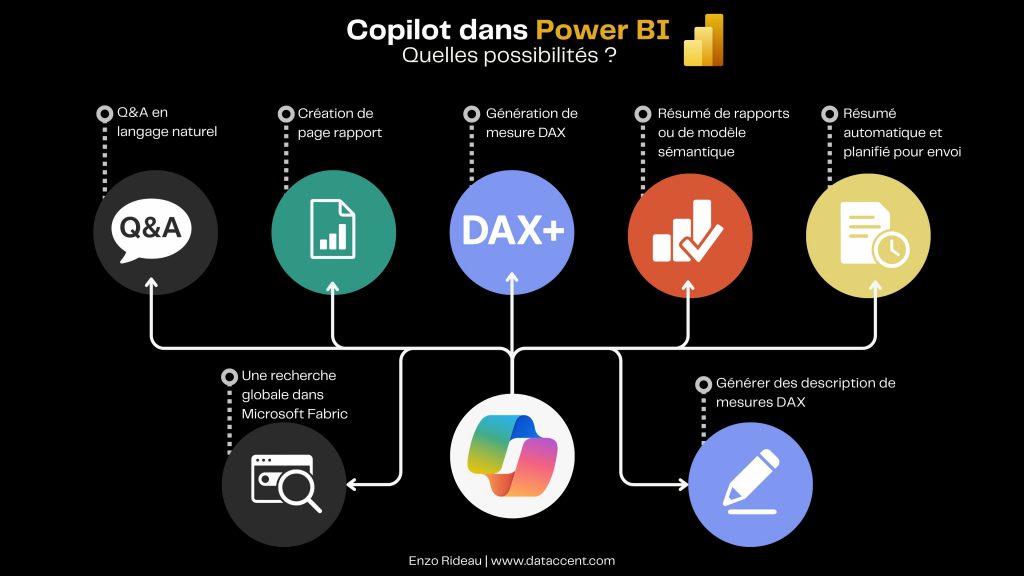
Fonctionnalités de Copilot dans Power BI
Création de rapports assistée par l’IA
Description : Copilot peut générer automatiquement une page de rapport à partir d’une simple instruction en langage naturel. L’utilisateur fournit un prompt (une description haut niveau de ce qu’il veut analyser) et Copilot identifie les tables, champs, mesures et visuels pertinents pour créer une ébauche de rapport complète powerbi.microsoft.com. Par exemple, en demandant « Construis un rapport sur les ventes par produit et région », Copilot va sélectionner les données appropriées et proposer des visualisations (graphiques, cartes, etc.) correspondant à la demande. Cette fonction est disponible dans Power BI Service (expérience web) et permet d’obtenir en quelques secondes un point de départ de rapport que l’on peut ensuite affiner manuellement. Copilot peut aussi suggérer des éléments de contenu supplémentaires pour les pages de rapport (par exemple, d’autres indicateurs ou visuels à ajouter) en se basant sur la structure du modèle de données powerbi.microsoft.com.
Cas d’usage concret (contrôleur de gestion) : Un contrôleur de gestion doit préparer rapidement un rapport mensuel sur les dépenses et le budget par département. Sans être expert de Power BI, il décrit simplement à Copilot le besoin (« Rapport comparant dépenses réelles vs budget par département ce mois-ci ») et obtient instantanément une page de rapport pré-remplie. Il y retrouve, par exemple, un graphique par département avec les dépenses réelles et budgétées, et un visuel de synthèse des écarts. Il ne lui reste qu’à vérifier et ajuster la présentation ou les filtres éventuels. Copilot lui a fait gagner un temps précieux en générant la trame du rapport en quelques clics.
Avantages :
Gain de temps et simplicité : La génération automatique de rapports accélère grandement le démarrage d’une analyse. Elle évite de partir d’une page blanche et réduit l’effort de recherche des champs ou visuels appropriés. Même un utilisateur non spécialiste peut obtenir un premier jet de rapport en décrivant ses besoins.
Accessibilité pour les non-techniques : Cette fonctionnalité démocratise la création de rapports. Un contrôleur de gestion, peu familier avec la modélisation ou DAX, peut tout de même produire un rapport de qualité en se reposant sur Copilot. Cela encourage la self-service BI au sein des équipes métier.
Personnalisation ultérieure : Le rapport généré sert de base modifiable. L’utilisateur conserve la main pour ajuster les visuels, appliquer la charte graphique de l’entreprise, ou affiner les calculs. Copilot fait une proposition, mais le contrôle final reste à l’humain.
Limites et considérations :
Pertinence variable : Le rapport créé automatiquement peut ne pas correspondre exactement à l’attente. Copilot sélectionne les visuels et mesures qu’il estime pertinents, mais il pourrait en oublier ou en choisir d’inadaptés selon le contexte métier spécifique. Il faut souvent prévoir des ajustements manuels.
Dépendance au modèle de données : Copilot ne peut bâtir un rapport qu’à partir des données et mesures disponibles dans le modèle Power BI. Si le modèle est incomplet ou mal structuré, la proposition en souffrira. Un modèle bien conçu (avec des mesures DAX prêtes, des relations claires) améliorera la qualité du rapport généré.
Préversion / configuration : En juin 2025, la création de rapports via Copilot est disponible en preview et requiert l’activation de Copilot sur un espace de travail Premium (Fabric ou PPU). L’administrateur tenant doit avoir activé Copilot, et idéalement en anglais car le support du français est limité (voir plus bas).
Considérations de confidentialité : La génération étant réalisée via un LLM hébergé (Azure OpenAI), les données et métadonnées du modèle sont envoyées au service pour analyse. Selon les politiques internes, il convient de vérifier l’activation du traitement hors zone si les données ne sont pas hébergées aux États-Unis ou en Europe (France), et de sensibiliser aux aspects RGPD si nécessaire.
Analyse conversationnelle en langage naturel (Q&A)
Description : Copilot permet d’interroger les données en langage naturel et d’obtenir des réponses instantanées sous forme de texte, de chiffre ou de visualisation. Deux modes sont disponibles : le Copilot dans le volet latéral d’un rapport (appelé aussi report Copilot ou agent de rapport) et l’expérience Copilot autonome en plein écran. Le volet Copilot (accessible dans Power BI Desktop ou Service sur un rapport ouvert) se focalise sur le jeu de données du rapport en cours, tandis que le Copilot autonome (accessible depuis la navigation de Fabric en préversion) permet de poser des questions sur n’importe quelle donnée à laquelle l’utilisateur a accès, en allant chercher le rapport ou le modèle pertinent pour répondre. Dans les deux cas, l’utilisateur peut simplement taper une question comme il le ferait avec un collègue analyste – par exemple « Quel était le chiffre d’affaires des produits alimentaires en France en 2023 ? » – et Copilot comprend la requête, va chercher les données nécessaires et fournit une réponse. Souvent, la réponse prend la forme d’un visuel généré dynamiquement (un graphique, un tableau) accompagné d’une phrase explicative powerbi.microsoft.com. Si le modèle ne contient pas déjà une mesure pour la question posée, Copilot est capable de créer une mesure DAX ad hoc en coulisse pour y répondre powerbi.microsoft.com. L’expérience est donc celle d’un chatbot de données directement intégré dans Power BI, qui permet un question-réponse interactif sur les données de l’entreprise.
Cas d’usage concret (contrôleur de gestion) : Un contrôleur de gestion utilise un rapport Power BI de pilotage financier. Certaines questions n’ont pas de visuel dédié dans le rapport. Par exemple, « Quels sont les 5 clients qui contribuent le plus à la marge cette année ? ». Au lieu d’exporter les données vers Excel ou de filtrer manuellement le rapport, il pose la question dans Copilot. L’IA lui renvoie instantanément un classement des 5 meilleurs clients par marge sous forme de tableau, tiré du modèle de données, avec éventuellement un graphique en barres. Il peut alors affiner : « Et qu’en est-il l’année précédente ? », Copilot comprend le contexte et met à jour la réponse. Grâce à cet échange en langage naturel, le contrôleur obtient ses réponses en quelques secondes, sans faire appel à l’équipe BI.
Avantages :
Interactivité et rapidité : Copilot agit comme un assistant analytique disponible à tout moment pour répondre aux questions ad hoc. Cela accélère grandement la prise de décision, en évitant d’attendre la création d’un nouveau visuel par un analyste. On obtient immédiatement l’information souhaitée sous forme exploitable powerbi.microsoft.com.
Flexibilité d’analyse : L’utilisateur peut explorer les données librement par un dialogue naturel, en rebondissant avec des questions de plus en plus précises. Copilot gère le contexte de la conversation (dans une certaine mesure) et permet un exploratoire guidé par l’IA. Par exemple, après un résultat global, on peut demander un détail par produit, etc., sans avoir à reconstruire manuellement des filtres ou mesures.
Création automatique de visuels et mesures : Un atout majeur est la capacité de Copilot à générer un visuel ou un calcul DAX temporaire pour répondre à la questionpowerbi.microsoft.com. L’utilisateur non techniquement outillé peut ainsi réaliser des analyses qui normalement nécessiteraient de créer une nouvelle mesure ou de modifier le rapport. Copilot s’occupe de la couche technique, l’utilisateur se concentre sur la question métier.
Respect de la sécurité : Copilot n’accède qu’aux données pour lesquelles l’utilisateur a les droits. Dans l’expérience autonome, l’IA respecte les permissions et la sécurité au niveau des lignes (RLS) configurées powerbi.microsoft.com. Un contrôleur peut donc l’utiliser en confiance dans le cadre de son rôle, sans crainte de divulguer des informations hors de son périmètre.
Limites et considérations :
Langue et compréhension : Actuellement, Copilot offre ses meilleures performances en langue anglaise. L’utilisation en français ou autre langue n’est pas officiellement supportée en juin 2025, même si des réponses pertinentes peuvent parfois être obtenueslearn.microsoft.com. Un contrôleur de gestion francophone pourrait devoir formuler ses questions en anglais pour que l’IA les comprenne parfaitement. C’est une contrainte linguistique importante, même si Microsoft travaille à l’élargissement multilingue.
Interprétation du jargon métier : Copilot se base sur les noms de colonnes, mesures et métadonnées du modèle pour comprendre les questions. Si le modèle utilise des termes techniques ou des abréviations propres à l’entreprise, il peut ne pas les saisir. D’où l’intérêt de bien nommer les champs et d’ajouter des synonymes aux termes métiers dans le modèle. D’ailleurs, des outils intégrés permettent d’enrichir le modèle (synonymes, descriptions) pour guider l’IA. Sans cette préparation, il peut y avoir des malentendus (par ex. « CA » interprété comme California au lieu de Chiffre d’Affaires).
Contexte limité et questions complexes : Copilot excelle sur des questions simples et directes. Des questions très complexes ou multi-étapes peuvent le dérouter. Par exemple, « Compare la croissance du chiffre d’affaires trimestriel avec l’évolution des effectifs sur la même période et explique l’impact sur la rentabilité » serait probablement trop élaboré pour une réponse directe. Il faut savoir découper les questions ou accepter que l’IA puisse fournir une réponse partielle.
Mode lecture vs édition : À ce stade, certaines capacités (comme la création de mesures ad hoc) sont disponibles uniquement en mode édition du rapport, pas pour un simple consommateur en mode lecture powerbi.microsoft.com. Autrement dit, un business user qui consulte un rapport publié peut poser des questions sur les données existantes, mais si la question nécessite un calcul inédit, Copilot pourrait ne pas la traiter à moins d’être en mode auteur. C’est une limitation temporaire en preview.
Fiabilité des résultats : Il convient enfin de garder un esprit critique sur les réponses de l’IA. Copilot peut se tromper ou renvoyer un visuel non pertinent s’il interprète mal la question ou si les données présentent des particularités. L’utilisateur doit valider que la réponse correspond bien à la réalité métier (par recoupement, vérification rapide des chiffres). Copilot est un assistant, pas une garantie absolue de vérité.
Résumés automatiques et narrations intelligentes
Description : Copilot intègre des capacités de résumé automatique de données pour extraire et communiquer les points saillants d’un rapport. Concrètement, deux fonctionnalités liées existent : d’une part la possibilité de demander un résumé via le chat Copilot (par exemple « Donne-moi les principales tendances de ce rapport »), et d’autre part le visuel Narrative with Copilot (anciennement Smart Narrative) qu’on peut insérer dans une page de rapport. Dans le premier cas, Copilot analyse l’ensemble du rapport ou une page spécifique et génère une réponse textuelle mettant en avant les informations importantes (hausse ou baisse notable, tendances, anomalies) en citant éventuellement quelques visualisations du rapport pour illustrerpowerbi.microsoft.compowerbi.microsoft.com. Il s’agit d’un résumé dynamique que l’IA rédige en quelques secondes. Dans le second cas, le visuel narratif inséré dans le rapport agit de manière similaire : l’utilisateur peut paramétrer ce visuel (par exemple « résumer cette page en 5 points clés ») et Copilot génère automatiquement du texte qui sera affiché dans le rapport, avec la possibilité de le mettre à jour lorsque les données changentpowerbi.microsoft.com. Ce texte peut couvrir soit les insights de la page active, soit l’ensemble du rapport, soit même être basé sur un template personnalisé (l’utilisateur peut orienter la narration sur certains indicateurs). L’objectif de ces fonctionnalités est de faciliter l’interprétation des données en fournissant une analyse écrite automatique compréhensible par tous.
Cas d’usage concret (contrôleur de gestion) : En préparation d’une réunion mensuelle, un contrôleur de gestion examine un tableau de bord complexe avec de nombreuses visualisations financières. Plutôt que de parcourir chaque graphique manuellement, il utilise Copilot pour générer un résumé des insights clés du mois. L’IA pourrait par exemple indiquer : « Les ventes globales sont en hausse de 8 % par rapport au mois dernier, portées principalement par la région Europe (+15 %). Cependant, la marge a chuté de 3 points, en raison d’une augmentation des coûts matières aux États-Unis… » et ainsi de suite, en listant 4–5 observations marquantes. Le contrôleur de gestion gagne du temps dans son analyse et peut utiliser ces éléments comme base pour son commentaire de gestion. De plus, il intègre un visuel narratif directement dans son rapport Power BI, ce qui permet aux décideurs de voir, en un coup d’œil texte + chiffres, les faits saillants sans devoir creuser chaque visuel.
Avantages :
Vue d’ensemble immédiate : Les résumés générés par Copilot fournissent une synthèse éclairante de jeux de données potentiellement complexes. En quelques phrases, l’IA peut faire ressortir des tendances ou anomalies qui auraient pu nécessiter de longues minutes d’analyse manuelle. Cela aide le décideur à se concentrer sur l’essentiel.
Communication facilitée : Le visuel narratif Narrative with Copilot permet d’intégrer directement dans un dashboard des commentaires automatiques. C’est très utile pour la communication financière ou le reporting : le texte explicatif s’actualise avec les données, évitant d’avoir à réécrire des analyses chaque mois. Pour un contrôleur de gestion, c’est un gain de temps et l’assurance que chaque lecteur du rapport comprendra les principaux enseignements.
Personnalisation du résumé : L’utilisateur peut demander un résumé général ou ciblé sur un sujet précis (« Que faut-il savoir sur les ventes de vélos en région X ? »). Copilot peut alors concentrer le commentaire sur un sous-ensemble pertinentpowerbi.microsoft.com. De plus, en mode visuel narratif, on peut paramétrer le niveau de détail (nombre de points, portée du résumé) selon les besoins.
Formation du regard analytique : Pour les utilisateurs moins expérimentés, voir ce que Copilot met en avant dans un rapport peut servir de guide. Cela met en lumière les éléments jugés importants par l’IA (souvent cohérents avec ce qu’un analyste humain noterait), et peut aider à apprendre à lire un rapport de façon efficace.
Limites et considérations :
Qualité variable de la narration : Si l’intention est excellente, il faut noter que le texte généré peut parfois rester générique ou peu précis. Par exemple, l’IA pourrait formuler « les ventes ont augmenté » sans mentionner un chiffre exact ou une cause précise. Elle peut aussi passer à côté d’un insight que vous, en tant qu’expert métier, auriez relevé. Le résumé automatique ne remplace pas l’analyse humaine et doit être relégué au rang de brouillon à affiner idéalement.
Langue du résumé : Comme pour le Q&A, la génération de texte narratif par Copilot se fait naturellement en anglais par défaut. Un utilisateur francophone obtiendra donc le plus souvent un résumé en anglais qu’il devra traduire ou reformuler. Microsoft n’a pas encore ouvert la génération multilingue pour ces fonctionnalités en juin 2025. C’est un frein pour une utilisation telle quelle dans des rapports destinés à des lecteurs non anglophones.
Dépendance aux données d’entrée : Le résumé ne peut être meilleur que les données et visuels sous-jacents. Si le rapport comporte des informations erronées ou incomplètes, Copilot pourrait mettre en avant des conclusions erronées. De même, si le rapport est très surchargé, l’IA pourrait avoir du mal à choisir les points clés pertinents. Un rapport clair, bien structuré, favorisera un meilleur résumé.
Considérations organisationnelles : L’intégration de textes générés automatiquement dans des communications officielles (rapports financiers, par exemple) doit être maniée avec prudence. Il convient de relire et valider ces textes, et possiblement de les adapter au ton de l’entreprise. Par ailleurs, certaines organisations peuvent hésiter à laisser une IA générer des commentaires sans validation, pour des raisons de confiance ou de responsabilité (notamment si une conclusion s’avère fausse a posteriori). Un bon usage est de s’en servir comme base de travail pour le contrôleur, plutôt que de le diffuser tel quel sans relecture.
Génération de mesures DAX et requêtes avancées
Description : Rédiger des formules DAX est souvent considéré comme l’une des tâches les plus techniques dans Power BI. Copilot vient simplifier cela en offrant deux approches : la génération de mesures DAX à la demande et l’écriture de requêtes DAX dans un éditeur dédié. D’une part, comme évoqué précédemment, Copilot est capable de créer à la volée une mesure non existante si une question posée l’exige (par ex., calculer un taux de croissance annuel qui n’est pas déjà dans le modèle)powerbi.microsoft.com. D’autre part, Power BI intègre un DAX query view (éditeur de requête DAX) où l’on peut formuler des demandes de création ou d’explication de code DAX, et Copilot va proposer le code correspondant powerbi.microsoft.com. Par exemple, un auteur peut ouvrir l’éditeur, cliquer le bouton Copilot, et demander « Écris-moi une mesure DAX pour calculer le churn des clients sur 12 mois glissants ». Copilot utilisera le contexte du modèle (colonnes disponibles, hiérarchies de dates, etc.) et générera une formule DAX plausible. Il peut aussi expliquer une formule existante si on lui demande. Au fil des mois, Microsoft a amélioré cette capacité : Copilot utilise désormais les descriptions, synonymes et exemples de valeurs fournis dans le modèle pour affiner ses suggestions de code. Il prend en compte les hiérarchies et dossiers de mesures définis par l’utilisateur pour mieux structurer la requête powerbi.microsoft.com. En somme, Copilot joue le rôle de « pair programmer » pour le développeur Power BI, en assistant la création de formules complexes et en automatisant une partie du travail de codage DAX.
Cas d’usage concret (contrôleur de gestion) : Un contrôleur de gestion avancé, qui modélise lui-même certaines données dans Power BI, a besoin de calculer un indicateur financier particulier – disons le Coût moyen par unité produite ajusté des variations de stock. Il n’est pas sûr de comment l’implémenter en DAX. En langage naturel, il décrit cette mesure à Copilot (dans l’éditeur DAX ou même via le chat du rapport en mode auteur). Copilot lui génère une formule DAX complète incorporant les éléments requis (par ex. utilisant SUMX sur la production en tenant compte de la variation de stock initial/final). Le contrôleur n’a plus qu’à tester cette mesure dans son modèle. Si la formule est trop complexe, il peut aussi demander à Copilot « Peux-tu expliquer cette formule ? » pour obtenir un décryptage pas à pas. Cela l’aide à valider la logique et à apprendre par la même occasion.
Avantages :
Aide à la conception DAX : Copilot réduit significativement la courbe d’apprentissage de DAX. Pour un utilisateur métier, pouvoir obtenir une base de mesure fonctionnelle à partir d’une description en langage courant est très appréciable. Cela permet de créer des indicateurs sur mesure sans attendre le support d’un expert BI.
Gain de productivité pour les experts : Même les développeurs Power BI chevronnés peuvent y trouver leur compte. Copilot agit comme un assistant code qui génère du DAX standard rapidement (par exemple pour des patterns connus comme Year-over-Year Growth, Moving Average, etc.), ce qui peut accélérer le développement. On peut ensuite peaufiner le code généré plutôt que de l’écrire intégralement soi-même.
Réduction des erreurs : En passant par un outil automatisé, on limite certaines erreurs de syntaxe ou oublis de filtre contextuel courants lors de l’écriture manuelle. Copilot, en s’appuyant sur le modèle et les bonnes pratiques, produit généralement un DAX correct (même s’il faut toujours tester). Par ailleurs, sa capacité d’expliquer le code aide à repérer où ajuster si le résultat n’est pas attendu.
Documentation plus riche : Grâce à Copilot, on peut aussi générer les descriptions des mesures dans le modèle. C’est un avantage organisationnel : souvent les mesures DAX manquent de documentation. Ici, l’IA peut proposer automatiquement un descriptif clair de ce que fait chaque mesure, ce qui facilite le partage et la maintenance du modèle.
Limites et considérations :
Exactitude du DAX généré : La principale réserve est la qualité du DAX produit. Copilot utilise un modèle statistique, il peut donc proposer une formule qui “semble” correcte mais qui, dans le contexte particulier du modèle, ne l’est pas. Par exemple, il pourrait ignorer un filtre important ou mal gérer un cas d’usage particulier (calcul en cumul sur année fiscale différente, etc.). Il est impératif de vérifier les résultats de toute mesure générée avant de la considérer comme acquise.
DAX complexe ou non standard : Copilot se débrouille bien sur les formules courantes, mais pour des besoins très spécifiques ou optimisations pointues (par ex. utilisation de variables de table intermédiaires, code ultra-optimisé pour gros volumes), l’IA peut atteindre ses limites. Le code proposé peut fonctionner mais ne pas être optimal en performance, ou parfois il déclarera ne pas savoir faire si la demande sort trop des sentiers battus.
Nécessité d’un modèle bien décrit : Comme mentionné, Copilot s’appuie sur les métadonnées. Si les tables/colonnes ont des noms peu explicites et aucune description, l’IA manque de contexte et peut se tromper de champ ou d’agrégation. Investir du temps à documenter le modèle (via les propriétés de description, les synonymes, etc.) est une bonne pratique pour fiabiliser les suggestions DAX de Copilot powerbi.microsoft.com.
Compétences de l’utilisateur : Paradoxalement, bien que Copilot permette à des novices de créer du DAX, un minimum de compétences reste utile pour valider et maintenir ces mesures. Un contrôleur de gestion ne connaissant rien au DAX pourrait produire une mesure via Copilot, mais si celle-ci nécessite un débogage ou une adaptation, il devra quand même comprendre un peu la logique. Copilot doit être vu comme un outil d’assistance plutôt que comme un remplacement total de la compétence technique.
Disponibilité : La génération de DAX via Copilot est apparue en préversion et requiert là aussi l’environnement Fabric/Premium activé. De plus, l’interface d’édition (DAX query view) n’est pas forcément connue de tous les utilisateurs car elle est relativement nouvelle dans Power BI. Il faut savoir où l’activer et y accéder (par exemple, elle peut être activée dans Power BI Desktop depuis février 2025 pour profiter de Copilot en écriture de requête).
Préparation du modèle et personnalisation de Copilot
Description : Pour tirer le meilleur de Copilot, Microsoft a introduit des outils permettant de préparer vos modèles de données pour l’IA et d’orienter ses réponses. Ces fonctionnalités, encore en préversion, s’adressent plutôt aux concepteurs de modèles (Data Analysts / BI) qu’aux utilisateurs finaux, mais il est utile d’en avoir conscience. Parmi elles : la définition d’un AI Data Schema (schéma de données pour l’IA), les Verified Answers (réponses vérifiées) et les AI Instructions (instructions supplémentaires). L’AI Data Schema permet de sélectionner un sous-ensemble de tables/champs du modèle que Copilot utilisera en priorité dans ses réponses. Cela revient à réduire le champ pour qu’il se concentre sur les données les plus pertinentes, évitant qu’une table périphérique ou un champ technique ne vienne perturber une réponse. Les Verified Answers, elles, offrent la possibilité d’enregistrer des réponses validées à l’avance pour certaines questions types : si l’utilisateur pose une question correspondante, Copilot renverra la réponse pré-approuvée (par exemple un visuel précis du rapport). C’est un moyen d’assurer la fiabilité sur des questions récurrentes et cruciales. Enfin, les AI Instructions permettent d’injecter du contexte ou des consignes particulières que Copilot devra suivre lors de ses analyses : par exemple « ne considérer que les données postérieures à telle date » ou « lorsqu’on parle de ‘profit’, utiliser la mesure X du modèle »powerbi.microsoft.com. Ces instructions guident l’IA pour qu’elle respecte les règles métiers de l’organisation. Pour faciliter tout cela, Power BI Desktop propose un bouton Préparer les données pour l’IA qui regroupe ces paramètres en un dialogue, à côté du bouton Copilot.
Cas d’usage concret (contrôleur de gestion) : Si le contrôleur de gestion est également propriétaire du dataset, il peut travailler avec l’équipe BI pour « éduquer » Copilot sur son modèle financier. Par exemple, dans un modèle de reporting financier, il peut définir comme schéma IA uniquement les tables de faits et dimensions pertinentes en excluant des tables techniques ou temporaires. Il peut également définir une réponse vérifiée pour la question « Quels sont les KPI principaux ce mois-ci ? », de sorte que Copilot présentera toujours le visuel de synthèse officiel approuvé dans le rapport. De plus, sachant que le terme “bénéfice” porte à confusion, il ajoute une instruction : « lorsque l’utilisateur dit bénéfice, interpréter comme Résultat Net ». Avec ces préparations, lorsqu’un collègue utilisera Copilot sur ce dataset, les réponses seront plus fiables, mieux cadrées et alignées sur le discours financier officiel de l’entreprise.
Avantages :
Amélioration de la pertinence : En limitant le périmètre de l’IA aux données importantes (via l’AI Data Schema) et en fournissant des synonymes/instructions, on obtient des réponses plus précises et pertinentes. On réduit le risque de confusion de Copilot face à un modèle riche.
Confiance accrue dans les réponses : Les réponses vérifiées permettent d’institutionnaliser certaines réactions de Copilot. Pour des questions sensibles (par ex. un indicateur réglementaire), on s’assure que la réponse de l’IA sera exactement celle validée par l’expert métier, renforçant la confiance des utilisateurs finaux.
Alignement sur le métier : Les instructions et champs personnalisés permettent d’aligner Copilot sur le langage et les règles de l’entreprise. On obtient un assistant sur-mesure, qui connaît par exemple la différence entre “ventes” et “facturation” telle que définie en interne, ou qui sait qu’un « client inactif » se définit selon un critère précis de la direction.
Gestion du changement facilitée : Au lieu de brider complètement Copilot par crainte d’erreurs, ces outils offrent une approche de gouvernance proactive. Les équipes Data/BI peuvent encadrer l’IA, ce qui rassure les responsables (DSI, finance) et facilite l’adoption de Copilot par les contrôleurs de gestion et autres analystes dans l’organisation. On peut bénéficier de l’innovation tout en gardant un certain contrôle.
Limites et considérations :
Effort de configuration : Mettre en place un AI Data Schema, renseigner des réponses vérifiées, etc., demande du temps et une bonne compréhension des questions fréquemment posées. C’est un investissement initial qui peut freiner certaines équipes si elles manquent de ressources.
Maintenance continue : Le modèle de données évoluant (nouvelles mesures, changements business), il faudra penser à mettre à jour ces paramètres (ajouter les synonymes pour de nouveaux champs, actualiser une réponse vérifiée si le KPI change de définition…). Cela introduit une forme de maintenance supplémentaire dans le cycle de vie du rapport.
Fonctionnalités en préversion : En juin 2025, ces outils de préparation sont en preview, donc susceptibles de changer. Il peut y avoir quelques bugs ou limitations (ex : longueur max des descriptions prises en compte par l’IA, qui est d’environ 200 caractères powerbi.microsoft.com). De plus, seuls les tenants Power BI hébergés dans certaines régions peuvent en profiter pleinement pour l’instant.
Portée limitée aux modèles enterprise : Ces fonctionnalités s’adressent surtout aux jeux de données centralisés et robustes, gérés par l’entreprise. Dans un usage purement personnel ou exploratoire, un contrôleur de gestion ne va pas s’amuser à configurer tout cela juste pour lui-même. Le bénéfice se concrétise vraiment dans une optique de BI gouvernée à l’échelle, où plusieurs utilisateurs consomment le même modèle via Copilot.
Perspectives d’évolution de Copilot dans Power BI
Copilot est une innovation encore récente dans l’écosystème Power BI, et son périmètre évolue rapidement. Voici quelques perspectives et évolutions attendues, basées sur les annonces Microsoft et les discussions de la communauté, à la date de juin 2025 :
Généralisation et montée en puissance – Microsoft indique sa volonté de rendre Copilot largement disponible. Lancé en préversion fin 2023, Copilot devrait passer en disponibilité générale (GA) lorsque sa fiabilité sera éprouvée. À court terme, on peut s’attendre à ce que l’expérience Copilot autonome (chat sur l’ensemble des données) passe en GA et soit activée par défaut dans le servicelearn.microsoft.com. De même, l’accès ne sera plus restreint aux capacités Premium : à terme, des licences Power BI Pro pourraient suffire si l’entreprise consomme du Fabric en ligne (sous réserve de puissances de calcul adaptées côté Microsoft). En parallèle, Microsoft continue d’améliorer le moteur AI derrière Copilot pour des réponses plus rapides, plus pertinentes, y compris sur des modèles volumineux.
Support multilingue complet – C’est une attente forte, notamment en Europe. Microsoft a déjà déployé Copilot en anglais (et partiellement en français pour d’autres produits comme Office Copilot). Pour Power BI, la roadmap prévoit l’extension à d’autres langues une fois les modèles linguistiques suffisamment entraînés. Le français et d’autres langues majeures devraient être supportés, permettant aux utilisateurs de poser leurs questions et recevoir des résumés directement en langue locale, de façon officielle et supportée. Cela impliquera aussi de gérer les formats locaux (dates, unités, etc.) dans les réponses de l’IA.
Intégration étroite avec Microsoft 365 et Fabric – On voit déjà poindre des intégrations, par exemple l’ajout d’un bouton dans Teams ou Outlook pour obtenir un Copilot summary d’un rapport Power BI partagépowerbi.microsoft.compowerbi.microsoft.com. À l’avenir, Copilot pourrait devenir omniprésent dans l’écosystème data : déclencher une analyse Power BI depuis une conversation Teams, incorporer un résultat de Copilot directement dans une présentation PowerPoint (au-delà de l’export actuel) ou dans un document Word sous forme de texte dynamique. Étant donné la stratégie Fabric (unifier BI, data science, ETL, etc.), on peut anticiper que Copilot saura naviguer à travers ces composantes : par exemple, expliquer la provenance d’une donnée depuis la source jusqu’au rapport, ou aider à générer une pipeline de données si une info manque pour un rapport. Microsoft investit également dans Copilot for Excel et autres outils ; on peut imaginer des interactions entre ces copilotes (Excel et Power BI se passant le relais pour répondre à une question).
Capacités analytiques et prédictives accrues – Pour l’instant, Copilot répond aux questions factuelles et fait des résumés descriptifs. Demain, on peut s’attendre à ce qu’il aille plus loin dans l’analytique avancée. Par exemple, la détection d’anomalies ou de causes pourrait être intégrée : on pourrait demander « Pourquoi les ventes ont chuté en mars ?» et Copilot utiliserait en arrière-plan les fonctions d’analyse de décomposition ou d’IA (déjà présentes dans Power BI) pour formuler une explication. De même, la frontière avec la prédiction pourrait s’estomper : Copilot, branché sur les capacités ML de Fabric, pourrait répondre à des questions prospectives (« Quel est le prévisionnel de ventes pour le prochain trimestre ? ») en faisant appel à un modèle de machine learning entraîné sur les données historiques. Ces évolutions transformeraient Copilot en un assistant non plus seulement descriptif mais aussi diagnostique et prédictif.
Feedback loop et amélioration continue – Microsoft apprend de chaque interaction utilisateur avec Copilot. On peut s’attendre à une amélioration continue de la compréhension des requêtes (via les retours d’usage). La communauté Power BI est très active et influence la roadmap : par exemple, des demandes pour que Copilot respecte mieux tel format de visualisation, ou qu’il puisse être personnalisé par domaine (finance, marketing…), pourraient voir le jour. À plus long terme, Microsoft pourrait ouvrir davantage Copilot à la personnalisation par le client : aujourd’hui on peut ajouter des instructions et réponses vérifiées, mais demain peut-être pourra-t-on entraîner un mini-modèle interne avec le jargon et les données de l’entreprise pour encore plus de pertinence.
Copilot dans Power BI va clairement monter en puissance. Microsoft en fait une pièce maîtresse de la BI augmentée, et ça se sent. Pour les contrôleurs de gestion et analystes, c’est une vraie bonne nouvelle : l’outil va devenir de plus en plus futé, tout en restant un copilote : pas un pilote. L’IA ne remplacera jamais le regard critique humain, mais elle va continuer à dégrossir le taf pour qu’on se concentre sur l’essentiel : l’analyse et les décisions.
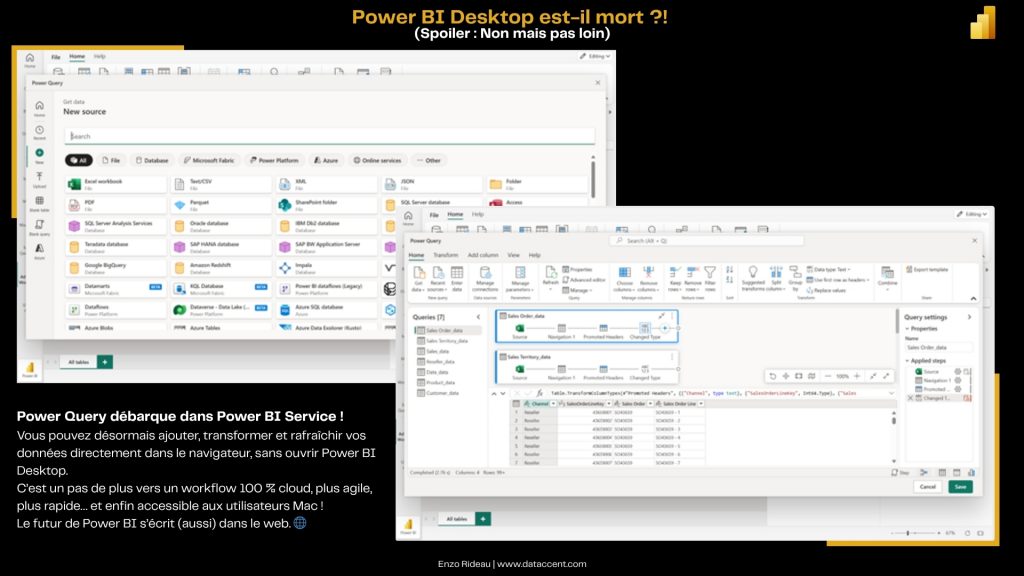
🚀 Power Query débarque dans le web : un pas de plus vers le Power BI full cloud
C’était probablement la dernière vraie pièce manquante dans l’édition d’un modèle Power BI directement depuis le web.
Depuis quelques jours, c’est officiel : Power Query est désormais disponible dans Power BI Service, en preview, pour les modèles en mode import.
Et clairement… ça change beaucoup de choses.
🔍 Concrètement, qu’est-ce qu’on peut faire ?
Dès aujourd’hui, vous pouvez :
Ajouter de nouvelles tables à votre modèle en ligne, via l’expérience “Get Data” qu’on connaît tous.
Transformer les données dans un éditeur Power Query intégré au navigateur, avec toutes les fonctionnalités clés (merge, filtre, typage…).
Rafraîchir les données et le schéma sans ouvrir Desktop, directement depuis le ruban du modèle.
Bref : l’essentiel de ce qu’on faisait dans Power BI Desktop peut maintenant se faire dans le navigateur.
Et pour beaucoup, c’est un game changer. Notamment pour les utilisateurs Mac, qui n’avaient jamais eu accès à Power BI Desktop de façon native. Pour eux, cette nouveauté est bien plus qu’un confort : c’est une libération.
⚒️ Et les outils externes dans tout ça ?
Autre annonce discrète, mais très importante : Les outils comme Tabular Editor, DAX Studio, ALM Toolkit… peuvent désormais effectuer des modifications complètes sur vos modèles, sans rollback au prochain refresh Desktop.
👉 Ajout de colonnes, modification de tables, ajustement des expressions DAX : tout reste en place.
C’est un vrai signal fort en faveur d’un environnement plus ouvert, plus modulaire, et plus robuste côté gouvernance.
🤔 Et maintenant… qu’est-ce qu’on fait de Power BI Desktop ?
Soyons clairs : Power BI Desktop n’est pas prêt de disparaître.
Mais, on le sent, Microsoft pousse progressivement vers une expérience cloud-first, cloud-native. Et ça pose une vraie question : est-ce qu’on peut imaginer, un jour, la fin de Power BI Desktop gratuit ?
🧠 Une analyse un peu plus critique…
Ce qui a fait le succès de Power BI, au départ, c’est aussi (et surtout) un point clé :
Power BI Desktop était gratuit. Et ça change tout.
C’est ce modèle qui a permis :
Une adoption massive dans les équipes métiers
Une approche bottom-up, sans budget ni commande d’outillage
Une démocratisation de la BI en self-service
C’est parce que Power BI Desktop était accessible sans friction qu’il a conquis aussi vite les analystes, les PMO, les contrôleurs de gestion, les RH…
Supprimer cette version gratuite serait, à mon sens, une erreur stratégique majeure pour Microsoft. Le modèle a toujours été clair :
Le client construit en local, découvre l’outil, et s’il veut collaborer, il prend une licence Pro ou entre dans l’environnement Fabric.
Ce tunnel-là, il fonctionne. Le casser, c’est risquer de bloquer l’entrée dans l’écosystème. Et ça, Microsoft le sait très bien.
🌐 Vers un monde Power BI full web ?
Oui, on tend vers une expérience web complète. Oui, le fait de ne plus avoir à installer quoi que ce soit, c’est une avancée majeure.
Mais soyons réalistes : certains usages avancés, certaines connexions spécifiques, et certains scénarios d’entreprise nécessitent encore Desktop.
Et plus largement, le fait de pouvoir démarrer gratuitement, sans abonnement, sans barrière technique restera un levier fort pour démocratiser l’outil. Même si l’interface web devient plus puissante… il faut préserver ce point d’entrée.
💬 En conclusion
Power Query dans le web, c’est une brique essentielle qui renforce un mouvement de fond : Power BI s’allège, se simplifie, devient plus accessible.
Mais ne nous trompons pas de combat : Le vrai atout de Power BI, c’est aussi sa capacité à séduire les utilisateurs là où ils sont, sans contrainte technique ou budgétaire.
Et dans ce modèle, Desktop gratuit reste une clé. À Microsoft de continuer à avancer sans renier ce qui a fait le succès de l’outil.
💬 Et vous, vous en pensez quoi ? Est-ce que vous êtes prêts à passer full web ? Ou Desktop reste encore incontournable dans votre quotidien ?
Une révolution silencieuse est en train de se jouer dans Power BI.
Depuis des années, la communauté en rêvait : pouvoir écrire dans la donnée directement depuis un rapport, sans passer par des formulaires externes, des outils tiers ou des contournements bricolés.
➡️ C’est désormais une réalité (en preview) avec les Translytical Task Flows.
Et spoiler : ça change beaucoup de choses.
🔍 De quoi on parle exactement ?
Les Translytical Task Flows, c’est une nouvelle fonctionnalité qui permet d’automatiser des actions dans un rapport Power BI. Des vraies actions. Pas juste du clic ou du filtre : on parle ici d’interaction bidirectionnelle avec la donnée, directement intégrée dans l’expérience utilisateur du rapport.
Techniquement, c’est rendu possible grâce aux Fabric User Data Functions, une couche de fonctions capables d’écrire dans une source de données en fonction du contexte de filtre du rapport.
🧠 Pourquoi c’est important ?
Parce que Power BI sort enfin de son rôle de “simple” outil de visualisation.
👉 Il devient un cockpit opérationnel, un assistant décisionnel, un point d’entrée vers l’action.
Jusqu’ici, un rapport Power BI répondait à la question :
“Que s’est-il passé ?” Désormais, il pourra aussi déclencher des choses comme : “Et maintenant, qu’est-ce qu’on fait ?”
🧪 Concrètement, on peut faire quoi ?
Voici quelques scénarios déjà possibles en preview :
✅ Modifier une donnée (ex. une remise)
Un utilisateur saisit une nouvelle valeur (ex : -15%) → clique sur un bouton “Appliquer la remise” → la donnée est mise à jour dans la base SQL Fabric, en fonction des filtres appliqués à l’écran.
🗨️ Ajouter un commentaire (annotation)
On peut sélectionner un point de données (ex : les ventes de février) → rédiger un commentaire → le voir apparaître immédiatement dans le rapport, et potentiellement le stocker dans la base.
✉️ Envoyer une notification ou un e-mail
Un utilisateur change un statut → un e-mail est envoyé automatiquement au contact associé, avec les infos du rapport.
🧾 Déclencher un workflow d’approbation
Un collaborateur propose une action (remise, nouveau contrat, etc.) → un manager est notifié → il valide ou rejette la demande depuis un autre rapport Power BI, déjà filtré.
🔍 Augmenter les données à la volée
Un rapport récupère automatiquement des infos complémentaires via API (ex : coordonnées d’un partenaire) pour enrichir le contexte.
🧠 Intégrer de l’IA sur mesure
Un bouton “Proposer une réponse” génère automatiquement un contenu avec Azure OpenAI, en fonction du contexte du rapport. Génial pour du contenu marketing, des résumés ou des préconisations.
🧱 Ça repose sur quoi ?
👉 Les bases SQL de Fabric, optimisées pour les opérations en lecture/écriture. 👉 Les Fabric User Data Functions, qui encapsulent la logique métier. 👉 Et bien sûr, l’intégration dans l’interface Power BI via des boutons, slicers, champs de saisie, etc.
Autrement dit : ce n’est pas une fonctionnalité 100% Power BI Desktop, c’est bien une brique Fabric, avec tout ce que ça implique (sécurité, gestion des accès, gouvernance…).
🤔 Est-ce que tout est parfait ? Pas encore.
Soyons lucides :
C’est encore en preview, donc non dispo partout, ni supporté en production officielle.
Il faut un minimum de compétences techniques sur Fabric pour mettre ça en place (SQL + Data Functions).
L’effet “formulaire dans Power BI” peut vite nuire à l’ergonomie si c’est mal pensé.
Et surtout : il faudra encadrer l’usage, pour éviter les dérives (ex : tout le monde modifie les données comme bon lui semble).
Mais malgré tout ça, on sent que le virage est pris.
🎯 Les cas d’usage que je vois tout de suite
Quelques exemples concrets que je trouve particulièrement prometteurs :
Suivi de plans d’action (avec commentaires + statut + notifications)
Gestion de projet (annotation, avancement, demandes)
Reporting RH (saisie des feedbacks, déclenchement de process)
RSE / CSRD (justification d’écarts, validation de seuils)
🚀 Et maintenant ?
👉 Si vous êtes déjà sur Fabric, testez cette nouveauté dès aujourd’hui. 👉 Si vous êtes encore sur un modèle 100% Power BI “classique”, c’est peut-être le bon moment pour s’y intéresser sérieusement.
Power BI ne se contente plus de raconter l’histoire. Il vous permet maintenant d’en écrire les prochaines lignes.
Power BI (UI/UX) : Comment concevoir un rapport qu’on a envie d’utiliser
Tu peux avoir le meilleur modèle de données, les mesures DAX les plus optimisées, des sources bien connectées… Mais si ton rapport est illisible, brouillon ou repoussant visuellement, alors il ne sera ni utilisé ni compris.
Un bon rapport Power BI, ce n’est pas juste une compilation de visuels. C’est une interface pensée pour délivrer le bon message, au bon moment, avec le bon design.
Voici un guide (presque) complet pour construire un rapport clair, structuré, agréable à lire, et qui donne envie de revenir.
1. Une page = une intention
Chaque page de rapport doit répondre à une seule question métier.
Exemples :
“Les ventes sont-elles en ligne avec les objectifs ?”
“Quels sont les produits qui sous-performent ?”
“Où se situent les pertes de marge par région ?”
Erreur fréquente : vouloir tout montrer sur une seule page. Résultat : on noie l’info, on perd le fil, et plus personne ne comprend rien.
🟡 Conseil : commence par poser la question à laquelle tu veux répondre — ensuite seulement tu construis la page.
2. Construis une hiérarchie visuelle
Un rapport n’est pas un collage de graphiques. Il doit guider la lecture naturellement.
Adopte une lecture en Z :
En haut à gauche → l’indicateur clé
En haut à droite → les éléments de contexte
En bas → les détails ou comparaisons
🛠️ Utilise :
Des titres clairs et visibles
Des tailles de police hiérarchisées (ex : 20px / 14px / 12px)
Des blocs visuels bien espacés
Des regroupements logiques par zone (thématiques, filtres…)
Bonus : crée un gabarit commun à toutes tes pages pour la cohérence visuelle.
3. Choisis une palette de couleurs sobre et cohérente
C’est probablement l’erreur la plus fréquente : trop de couleurs, ou mal utilisées.
🔸 Utilise :
1 à 2 couleurs dominantes (souvent les couleurs de la marque)
1 couleur d’alerte (rouge ou orange) pour attirer l’attention
Des tons neutres (gris, blanc, bleu clair) pour les éléments secondaires
🔸 Évite :
L’effet arc-en-ciel dans chaque graphique
Le rouge/vert pour signifier bon/mauvais (problèmes d’accessibilité visuelle)
Chaque graphique doit avoir une fonction précise :
Mettre en valeur un KPI
Comparer des évolutions
Montrer une répartition ou une anomalie
⚠️ Évite :
Les pie charts à 6 tranches et plus
Les visuels de « décoration »
Les dashboards à 10+ visuels par page
✔️ Privilégie :
Bar charts (verticaux ou horizontaux)
Line charts pour les évolutions temporelles
KPI cards simples et claires
Tableaux uniquement s’ils sont interactifs ou filtrables
🟡 Moins, c’est mieux. Et plus vite compris.
5. Utilise des filtres visibles et explicites
Un slicer en bas à droite, sans étiquette, sans logique ? C’est le meilleur moyen de perdre ton utilisateur.
🛠️ Bonnes pratiques :
Place les filtres en haut ou sur le côté gauche
Indique clairement à quoi ils servent (“Filtrer par produit”, “Sélectionner une année…”)
Utilise des types de filtres lisibles : listes déroulantes, boutons, sliders
Et si le filtre modifie fortement le contenu, ajoute un message explicite : “Vue actuelle : Région = Nord, Mois = Janvier”
6. Assure-toi que la typographie est lisibl
Utilise une police sans-serif (Segoe UI, Arial, Roboto…)
Ne descends pas en dessous de 12px pour le texte courant
Crée des repères visuels : titres plus grands, mise en gras, soulignés discrets
⚠️ Évite :
Le texte gris clair sur fond blanc
Les sauts de lignes excessifs
L’italique partout (illisible à l’écran)
🟡 Ton utilisateur doit pouvoir lire les infos sans plisser les yeux.
7. Soigne la navigation
Ton rapport est interactif ? Très bien. Encore faut-il que ça se voie.
✔️ Utilise :
Une page d’accueil claire avec des boutons vers les grandes sections
Un bandeau de navigation (signets, liens entre pages)
Des zones cliquables qui ressemblent à… des zones cliquables
🟡 Pense “site web” : tu guides ton visiteur d’un point A à un point B.
8. Ajoute du contexte métier et de l’humain
Les rapports froids et techniques ne parlent à personne.
Ajoute des éléments narratifs :
Une phrase de synthèse en haut (“Chiffre d’affaires en hausse grâce à la zone Sud”)
Des icônes simples pour renforcer un message (check, warning, flèche)
Des annotations contextuelles (“Valeur atypique suite à rupture de stock”)
🟡 Tu rends le rapport plus vivant, plus humain, plus lisible.
9. Pense responsive / accessibilité
Tu ne sais pas sur quel support sera lu ton rapport.
✔️ Vérifie :
Que les visuels s’affichent bien sur petit écran (zoom 80% / 100% dans Power BI)
Que la navigation est fluide à la souris comme au tactile
Que les couleurs sont lisibles pour les daltoniens ou les gens en fatigue visuelle
Astuce : Power BI a un “Mode contraste élevé” pour tester tes rapports.
10. Teste, itère, demande du feedback
Tu n’es pas ton utilisateur. Ce qui te semble évident ne l’est peut-être pas.
➡️ Fais relire le rapport à une personne non impliquée. ➡️ Observe où elle bloque, ce qu’elle lit en premier, ce qu’elle rate. ➡️ Adapte.
Le design, c’est jamais fini. Et c’est rarement parfait du premier coup.
Pour résumer
Un bon rapport Power BI, c’est :
Une question métier claire
Une structure visuelle cohérente
Un style sobre, lisible, accessible
Un design orienté utilisateur, pas développeur
Parce que ton rapport n’est pas là pour “montrer ce que tu sais faire en DAX”. Il est là pour aider quelqu’un à prendre une meilleure décision, plus vite, avec plus de confiance.
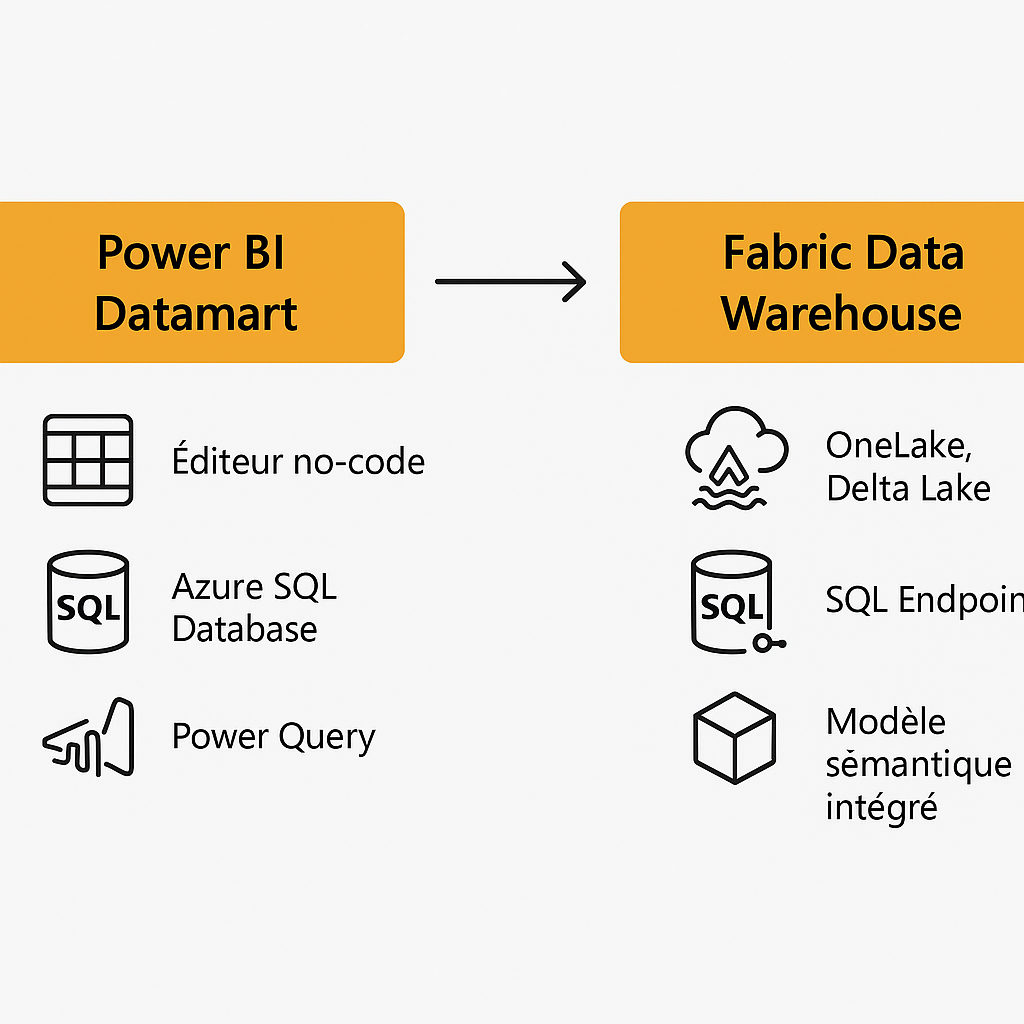
Le 2 mai 2025, Microsoft a annoncé officiellement la fin des datamarts dans Power BI. À leur place, la firme pousse désormais vers l’utilisation des Data Warehouses de Microsoft Fabric, une brique plus moderne, plus intégrée et plus cohérente avec la vision globale de la plateforme.
Mais est-ce réellement une mauvaise nouvelle ? Est-ce que quelqu’un utilisait vraiment les datamarts ? On reprend tout depuis le début.
C’était quoi un datamart Power BI, déjà ?
Les datamarts, lancés en mai 2022, avaient pour objectif de donner de l’autonomie aux analystes métier. Une sorte de « mini entrepôt de données » prêt à l’emploi, accessible depuis Power BI Service.
Concrètement, un datamart, c’était :
une interface no-code pour créer des tables relationnelles,
un moteur SQL sous Azure SQL DB,
Power Query pour gérer l’ingestion des données,
un modèle sémantique intégré utilisable directement dans un rapport.
Le tout dans une interface plutôt bien pensée, mais jamais vraiment adoptée massivement.
Pourquoi Microsoft les supprime ?
Officiellement, Microsoft met en avant trois raisons :
Une architecture isolée : les datamarts ne reposaient pas sur OneLake ni sur Delta Lake. Ils étaient techniquement à part.
Trop de recouvrement : entre dataflows Gen2, lakehouses, warehouses, notebooks… il fallait rationaliser.
Une vision unifiée avec Fabric : désormais, tout doit passer par le OneLake, avec une expérience unifiée, gouvernable, pilotable et évolutive.
En d’autres termes : les datamarts faisaient doublon et n’étaient pas alignés avec le futur de l’écosystème.
Et donc, on fait quoi maintenant ?
Microsoft recommande de se tourner vers les Data Warehouses Fabric, qui reprennent les fondamentaux des datamarts… mais en beaucoup plus solide.
Voici ce qu’on y retrouve :
Power Query pour l’ingestion,
Modèle sémantique Power BI intégré,
Requêtes SQL,
Stockage Delta Lake,
Intégration avec OneLake,
Meilleure performance et meilleure scalabilité,
CI/CD, Git, pipelines de déploiement, Copilot, sécurité centralisée…
En clair : c’est plus technique, mais c’est aussi beaucoup plus puissant.
Et pour ceux qui avaient déjà des datamarts ?
Il n’est plus possible d’en créer depuis mai 2025.
Les datamarts existants restent accessibles en lecture seule.
Pas d’outil de migration automatique : il faudra recréer les flux, les modèles et les logiques dans Fabric.
Il est donc conseillé de recenser vos datamarts, de documenter les transformations, et de planifier une transition manuelle vers Fabric.
Mon analyse : une bonne décision, mais pas sans impact
Soyons honnêtes : peu d’équipes utilisaient les datamarts sérieusement. Et ceux qui les utilisaient auraient tout intérêt à passer à Fabric dès maintenant. Car Fabric offre :
une vraie architecture cloud-native,
des performances nettement supérieures,
une logique de plateforme unique, bien plus lisible.
Mais…
L’effort de migration peut être significatif,
Les profils métier risquent de se sentir exclus (le datamart était accessible sans trop de bagage technique),
L’absence d’assistant de migration est un vrai manque.
Bref : c’est une avancée technologique, mais pas une transition transparente. Et comme souvent avec Microsoft, la simplification vient… après la complexité initiale.
Comment aborder la transition ?
Voici un plan simple pour accompagner ce changement :
Lister tous les datamarts existants dans l’organisation,
Identifier les sources, transformations et modèles utilisés,
Former vos équipes aux entrepôts Fabric (via la doc officielle ou des formations internes),
Créer un POC dans Fabric avec un cas métier équivalent,
Préparer la gouvernance Fabric (OneLake, workspaces, rôles, pipelines, etc.).
Conclusion
La disparition des datamarts signe la fin d’un outil hybride, certes intéressant sur le papier, mais peu exploité. Microsoft fait un choix stratégique : unifier l’expérience data autour de Fabric et OneLake.
Est-ce une perte ? Pas vraiment. Est-ce une opportunité ? Clairement.
Reste à accompagner le mouvement intelligemment. Et surtout, à ne pas oublier ceux qui avaient (quand même) adopté les datamarts : ils vont devoir tout reconstruire, sans filet.
Mais bon… soyons francs : on ne va pas pleurer longtemps.
On ne parle pas d’une nouveauté. Mais d’un rappel utile. Parce qu’entre deux dashboards et trois fichiers Excel, on oublie souvent à quel point Power BI, intégré à Office 365, peut vraiment simplifier la vie métier.
Tu bosses dans une équipe data, au contrôle de gestion ou côté business ? Voici ce que cette intégration change, concrètement, dans ta manière de travailler.
Cas d’usage : suivre sa performance commerciale sans y passer des heures
Prenons Sophie. Directrice commerciale dans une PME. Avant, chaque début de mois, c’était compilation manuelle des ventes dans Excel, rapport figé à la direction, et données déjà obsolètes au moment de la présentation.
Depuis qu’elle utilise Power BI connecté à Office 365, tout a changé. Elle a un dashboard interactif, à jour en temps réel, qu’elle peut filtrer à la volée en réunion. Chiffre d’affaires par région, suivi des objectifs, zoom sur les meilleurs produits ou commerciaux… tout est là, prêt à l’emploi.
Résultat : elle passe moins de temps à produire, plus de temps à analyser. Et surtout, elle peut prendre des décisions sur des données vivantes, pas sur des captures d’écran du mois dernier.
Cas d’usage complémentaire : un fichier CSV sur SharePoint qui devient un vrai outil de pilotage
Autre exemple : Julien, responsable qualité dans une entreprise industrielle. Chaque jour, ses équipes terrain remplissent un fichier CSV avec les incidents recensés sur les lignes de production. Ce fichier est automatiquement stocké dans une bibliothèque SharePoint, accessible à toute l’équipe.
Avant, Julien ouvrait le fichier chaque matin, filtrait les lignes à la main, puis copiait les données dans un PowerPoint pour son point quotidien avec les responsables d’atelier. Chronophage, répétitif, peu scalable.
Aujourd’hui, ce même fichier CSV est connecté en direct à Power BI. Le rapport s’actualise automatiquement dès qu’un collaborateur ajoute une ligne. Julien a désormais un tableau de bord clair : types d’incidents, fréquence, localisation, temps moyen de résolution, comparaisons par jour ou par atelier…
Et cerise sur le gâteau : ce rapport est intégré dans Teams, dans le canal de suivi qualité. Chacun peut le consulter, le commenter, et prendre des décisions dès qu’un problème est détecté.
→ Résultat : moins d’erreurs, plus de réactivité, et une équipe qui parle le même langage.
Une intégration fluide, sans changer d’environnement
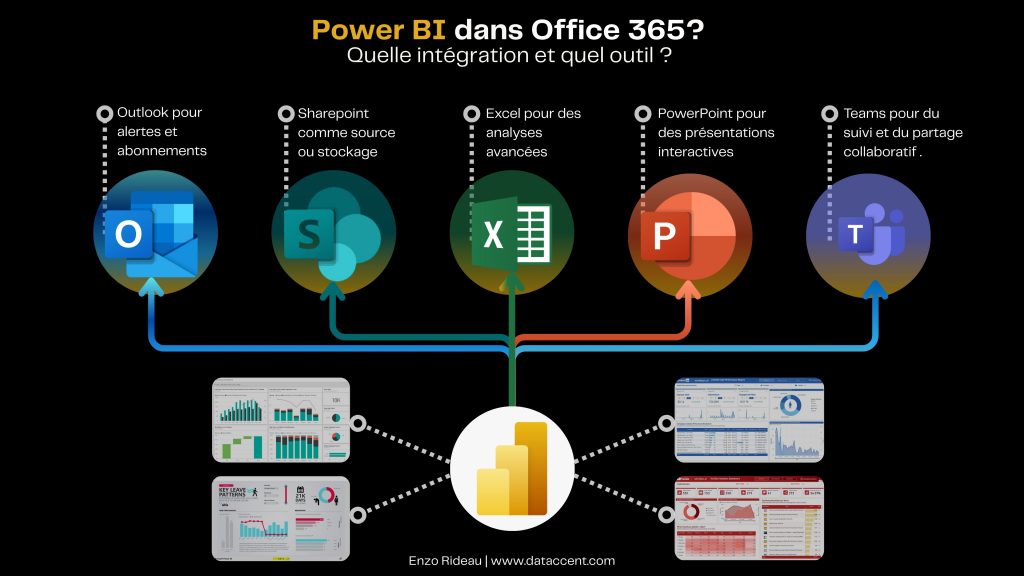
Ce qui fait la différence, c’est que Power BI ne travaille jamais seul. Il s’appuie sur les outils Office 365 que tu utilises déjà tous les jours. Et cette synergie, elle a un vrai impact au quotidien :
📊 Excel : Pas besoin de tout reconstruire. Tu connectes directement tes fichiers stockés dans OneDrive ou SharePoint, et ton dashboard se met à jour tout seul. Et dans l’autre sens ? Tu analyses ton modèle Power BI directement dans Excel avec des TCD dynamiques. Simple et efficace.
💬 Teams : Ton rapport est consultable directement dans ton canal d’équipe. Tu commentes les visuels, tu prends des décisions avec ton équipe, sans jamais quitter Teams. Et tu reçois même des alertes dès qu’un indicateur passe sous un seuil critique.
📁 SharePoint : Un rapport publié dans SharePoint devient accessible à tous. Et si tes données sont dans un fichier Excel stocké sur SharePoint ? Il alimente Power BI automatiquement, sans aucune manip manuelle.
📧 Outlook : Tu programmes l’envoi automatique de ton rapport chaque lundi matin. Et avec Power Automate, tu peux même déclencher des workflows plus poussés : notifier un manager, créer une tâche, lancer une action.
📽 PowerPoint : Tu exportes en un clic ton rapport pour une réunion. Les visuels sont propres, alignés, et tu peux les mettre à jour juste avant la présentation si besoin. Fini les captures d’écran.
☁️ OneDrive : Un fichier source bien rangé, bien connecté, et c’est tout un reporting qui reste à jour. Tu travailles sur une seule version du fichier, partagée avec toute l’équipe. Sans ressaisie. Sans friction.
📌 En clair : plus de clarté, moins de charge mentale
Power BI va bien plus loin que l’Excel classique. Tu as des visuels dynamiques, des interactions simples, une lecture rapide. Et surtout, tu n’as plus à tout refaire à chaque fois.
Tu planifies, tu automatises, tu pilotes. Tu fais parler la donnée sans y passer la journée.
💡 Conclusion : une suite cohérente, au service du métier
Power BI + Office 365, c’est un environnement unifié où les données circulent naturellement. Où les utilisateurs ne subissent plus la technique mais l’utilisent pour décider. Et même ceux qui ne sont pas experts peuvent s’y retrouver, comprendre les indicateurs et contribuer à la réflexion.
Alors si tu n’avais jamais pris le temps d’explorer tout ce que cette intégration permet… il est temps d’y jeter un œil.
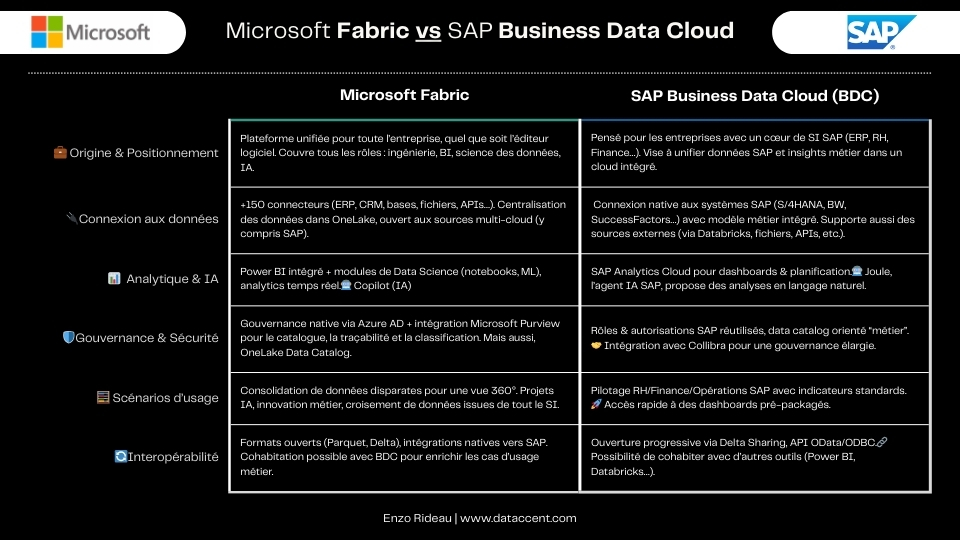
Dans le domaine de la Data Analytics orientée métiers, deux offres complètes retiennent l’attention en 2025 : Microsoft Fabric et SAP Business Data Cloud (SAP BDC). Ces plateformes analytiques unifiées proposent chacune une approche différente pour exploiter les données de l’entreprise. Sans tomber dans le buzz marketing, examinons les faits de manière pragmatique : quelles sont les forces de chaque solution, dans quels contextes les utiliser, et comment elles peuvent même cohabiter au service des métiers.
SAP Business Data Cloud en bref : le cloud data business par SAP
SAP Business Data Cloud (BDC) est la toute nouvelle plateforme Data & Analytics lancée par SAP en 2025. Il s’agit d’une solution cloud unifiée (SaaS) regroupant plusieurs services SAP existants et nouveaux : on y retrouve notamment SAP Datasphere (gestion de données et entrepôt cloud), SAP BW/4HANA (entrepôt de données SAP traditionnel, en option hébergée), SAP Analytics Cloud (BI & planning), l’assistant intelligent Joule (agent IA), ainsi qu’une intégration native de Databricks pour le traitement big data et le machine learning. En réunissant ces composants, SAP BDC vise à fournir un socle de données harmonisé avec contexte métier pour l’analytique et l’IA, particulièrement pour les entreprises déjà utilisatrices des solutions SAP.
Adaptation aux environnements SAP : Sans surprise, SAP BDC est optimisé pour les écosystèmes SAP. Il se connecte nativement aux applications SAP (ERP S/4HANA, SAP SuccessFactors, etc.) et réutilise les riches métadonnées métiers de SAP (modèles de données, indicateurs standards) pour donner du sens aux données. SAP met l’accent sur sa connaissance profonde des processus métier pour transformer les données en insights pertinents. BDC fournit d’ailleurs des data products préconstruits (jeux de données, modèles analytiques) et des « insight apps » prêtes à l’emploi pour de nombreux domaines fonctionnels, en s’appuyant sur SAP Analytics Cloud. Cela permet aux entreprises SAP d’accélérer la création de tableaux de bord et d’indicateurs métier avec un minimum d’effort, en profitant de contenus packagés basés sur les best practices.
Ouverture au-delà de SAP : Bien que centré sur les données SAP, BDC n’est pas pour autant une tour fermée. La plateforme se veut “ouverte” et extensible. Elle intègre par exemple nativement la technologie Databricks pour gérer des données non-SAP (datalake, fichiers, big data) au sein d’un lakehouse unifié. SAP BDC offre aussi des connecteurs et outils pour intégrer des données tierces : l’idée est de « connecter toutes vos données SAP et non-SAP » dans une solution SaaS unifiée (Source : sap.com). L’écosystème ouvert de SAP prévoit des intégrations avec des partenaires leaders comme Collibra (gouvernance des données) ou Confluent (streaming Kafka) afin d’élargir les capacités de la plateforme au-delà des seules solutions SAP. En résumé, SAP BDC est particulièrement à l’aise dans un contexte où le cœur du système d’information est SAP, tout en permettant d’incorporer d’autres sources pour offrir une vision complète des données d’entreprise.
Microsoft Fabric en bref : l’analytique unifiée tout-terrain
Lancé par Microsoft en 2023, Microsoft Fabric se présente comme une plateforme analytique unifiée de bout en bout pour l’ère de l’IAazure.microsoft.com. C’est une solution SaaS également, qui rassemble au sein d’un même environnement tous les outils nécessaires pour gérer un projet data du début à la fin. Concrètement, Fabric intègre des technologies bien connues de l’écosystème Azure/Microsoft : l’ingestion et l’intégration de données avec Azure Data Factory, le stockage et l’ingénierie de données avec OneLake (lac de données multi-cloud) et Synapse (ingénierie Spark, entrepôt data warehouse, analytics temps réel), la Data Science/IA ( notebooks Spark, modèles ML), et bien sûr la visualisation et le reporting avec Power BI. Le tout est interconnecté de manière transparente dans une expérience unifiée.
Transversalité et écosystème Microsoft : Microsoft Fabric est conçu pour être générique et polyvalent. Contrairement à SAP BDC, il n’est pas lié à un ERP en particulier : c’est une plateforme agnostique sur le plan technologique, capable de se connecter à un très large éventail de sources de données. En effet, grâce à Data Factory intégré, Fabric propose plus de 150 connecteurs prêts à l’emploi vers des sources cloud ou locales hétérogènes (bases SQL, applications SaaS, fichiers, API, etc.). Cette transversalité en fait un choix naturel pour les organisations dont les données sont dispersées entre différentes technologies ou éditeurs. De plus, Fabric est profondément intégré à l’écosystème Microsoft 365 : les utilisateurs peuvent facilement retrouver les données et rapports Power BI directement dans Teams, Excel, PowerPoint, SharePoint, etc., ce qui facilite l’adoption par les métiers habitués aux outils Microsoft.
En somme, Fabric s’adresse à un public large (ingénieurs data, data scientists, analystes, utilisateurs métier…) cherchant une plateforme unifiée pour tous types de données, dans la continuité des outils Microsoft déjà en place.
Peut aussi cohabiter avec SAP : La flexibilité de Microsoft Fabric lui permet également de s’intégrer dans un paysage incluant du SAP. Par exemple, il est tout à fait envisageable de connecter Fabric à des systèmes SAP via des connecteurs dédiés (API OData/ODBC, extracteurs SAP, etc.), afin d’y ingérer des données SAP et les combiner avec d’autres données de l’entreprise. Microsoft et SAP ont d’ailleurs une collaboration de longue date pour favoriser l’interopérabilité de leurs solutions (ex: certificats d’intégration, connecteur SAP pour Azure Data Factory, etc.). Fabric ne vise pas à remplacer les outils SAP Analytics dans leur terrain de prédilection, mais offre une option supplémentaire pour valoriser les données SAP aux côtés d’autres sources non-SAP. On peut ainsi très bien imaginer une cohabitation où les données SAP sont exploitées en parallèle par SAP BDC et par Microsoft Fabric, pour des usages complémentaires que nous aborderons plus loin.
Intégration des données : deux approches pour unifier les sources
Une des premières questions à se poser concerne l’intégration des données provenant de multiples sources (SAP ou non). Les deux plateformes offrent des solutions, avec des philosophies différentes liées à leur ADN.
SAP BDC : intégration “métier” des données SAP et au-delà. SAP Business Data Cloud excelle évidemment à intégrer les données des applications SAP de l’entreprise. Via SAP Datasphere (inclus dans BDC) et d’autres services, on peut se connecter directement aux systèmes SAP (par exemple S/4HANA, SAP BW, SAP SuccessFactors…) en profitant des vues métier existantes et des structures SAP. L’avantage est que les données gardent leur contexte métier SAP lors de l’intégration – les objets (ex: commandes, livraisons, factures) conservent leurs relations et significations. En outre, BDC permet d’intégrer des données non-SAP dans son lac de données central. Grâce à l’object store intégré (SAP HANA Data Lake Files) et à l’alliance avec Databricks, on peut charger ou virtualiser des données tierces (fichiers parquet, données data lakes externes, etc.) et les harmoniser avec les données SAP. SAP met en avant la capacité de connecter toutes les données SAP et non-SAP dans une solution unifiée sans avoir à sortir de l’écosystème. Cela réduit les besoins d’extraction et de duplication vers d’autres plateformes externes, évitant ainsi les coûts cachés et les délais liés à ces transferts.
En bref, pour une entreprise majoritairement SAP, BDC offre un hub central où rapatrier ou fédérer l’ensemble des données pertinentes, avec la promesse que l’intégration des données SAP y sera plus simple et plus riche en sens qu’ailleurs.
Microsoft Fabric : connectivité universelle et unification en lac de données. De son côté, Microsoft Fabric aborde l’intégration par le prisme de la diversité des sources. La plateforme embarque un service d’intégration (Data Factory) proposant 150+ connecteurs couvrant la plupart des technologies de données du marché.
Applications d’entreprise (y compris SAP via des connecteurs certifiés), bases de données SQL/NoSQL, services cloud, fichiers plats, flux IoT – rares sont les sources de données que Fabric ne peut pas brancher. Cette approche tout-terrain facilite la consolidation de données multi-cloud ou hybrides dans un lac de données unique appelé OneLake.
OneLake (fourni automatiquement avec Fabric) est un lac de données multi-tenant où atterrissent les données ingérées, organisées de façon cohérente et indexées pour être facilement découvertes et gouvernées.
Fabric unifie ensuite l’accès à ces données via divers moteurs (SQL, Spark, etc.) sans avoir à les déplacer de nouveau. En somme, l’intégration sous Fabric rime avec agilité et amplitude : on privilégie la centralisation des données disparates dans un lac unifié, avec une architecture cloud moderne, plutôt que l’optimisation spécifique d’une source en particulier. Pour une entreprise qui a des données réparties entre du SAP, du Salesforce, des bases Oracle et des fichiers Azure/AWS, Fabric fournit l’infrastructure intégrée pour tout connecter et tout analyser au même endroit.
Gouvernance et gestion des données : contrôle vs. ouverture
Intégrer des données massivement ne suffit pas ; il faut aussi garantir leur gouvernance, c’est-à-dire la qualité, la sécurité, la conformité et le suivi des données à travers la plateforme. Là encore, les deux solutions proposent des approches alignées sur leurs écosystèmes.
SAP BDC : gouvernance centrée sur le contexte métier SAP. Avec SAP BDC, les entreprises retrouvent les mécanismes de sécurité et de gouvernance propres à l’univers SAP. Par exemple, les modèles de données importés depuis SAP conservent les autorisations définies au niveau ERP ou BW, assurant que chaque utilisateur ne voit que ce qu’il doit voir. L’intégration serrée avec SAP Analytics Cloud permet de définir des règles de gouvernance au niveau métier (par ex. les indicateurs standardisés, les hiérarchies organisationnelles) et de les appliquer de façon cohérente dans les analyses. SAP BDC propose également un catalogue de données enrichi de sémantique : les data products définis sont documentés avec leur définition métier, ce qui aide à la compréhension et à la réutilisation des données. Pour élargir la gouvernance aux données non-SAP, SAP mise sur des partenariats : l’intégration avec Collibra notamment permet de gérer le catalogue et la qualité des données de façon avancée dans BDC. En résumé, la gouvernance dans BDC est très orientée “métier SAP”, avec la possibilité d’y adjoindre des outils spécialisés du marché. Ceci convient parfaitement aux entreprises voulant préserver la cohérence métier de leurs données de bout en bout, surtout si elles ont déjà des standards internes alignés sur SAP.
Microsoft Fabric : gouvernance unifiée via l’écosystème Azure. Microsoft Fabric, de par son ADN Azure, s’appuie sur les services de sécurité et gouvernance de Microsoft. L’authentification et les droits d’accès sont gérés via Azure Active Directory, offrant un contrôle fin des accès à chaque élément (datasets, notebooks, rapports). OneLake, le lac central de Fabric, indexe automatiquement les données pour en faciliter la découverte, le partage et la conformité réglementaire. De plus, Fabric peut être couplé à Microsoft Purview (solution de gouvernance de données Azure) pour cataloguer l’ensemble des données, tracer leur lignée (provenance) et appliquer des classifications/sensitivity labels. Chaque artefact créé dans Fabric (pipeline de données, modèle, rapport) peut être suivi et documenté, ce qui aide à garder la maîtrise sur l’écosystème analytique. En termes de sécurité, Fabric bénéficie de toute la pile Azure (chiffrement, gestion des clés, surveillance) et de l’intégration native avec les outils Microsoft 365 pour, par exemple, prévenir la fuite de données dans les rapports partagés (DLP). Ainsi, la gouvernance sous Fabric est intégrée par défaut et s’aligne sur les bonnes pratiques cloud de Microsoft. Elle sera familière aux équipes qui travaillent déjà sur Azure ou Power BI, et assure une ouverture nécessaire pour gérer des données très variées, au prix d’un effort de configuration possiblement plus technique initialement comparé à SAP BDC.
Analytique, BI et IA : quelles capacités pour les utilisateurs métier ?
Une plateforme analytique n’a de valeur que par les insights qu’elle permet de délivrer aux métiers, via des outils de Business Intelligence (BI), de visualisation ou même d’intelligence artificielle (IA). Comparons les offres de SAP BDC et de Microsoft Fabric sur ces aspects.
SAP BDC : SAP Analytics Cloud et l’IA métier intégrée. Du côté SAP, l’outil BI phare est SAP Analytics Cloud (SAC), inclus dans Business Data Cloud. SAC offre aux utilisateurs métier une interface 100% web pour créer des tableaux de bord interactifs, des visualisations et même des analyses ad hoc via du self-service. SAC est reconnu pour combiner à la fois de la BI classique (reporting, KPI) et des fonctionnalités de planification financière et simulation (budget, prévisions) dans le même outil – un atout pour les départements finance, RH, etc., qui peuvent à la fois analyser et planifier dans un environnement intégré. Avec BDC, SAP pousse encore plus loin l’IA intégrée dans l’expérience utilisateur grâce à Joule, son agent intelligent. Joule est un assistant IA (basé sur des technologies GPT, entraîné sur le contexte SAP) qui permet aux utilisateurs de poser des questions en langage naturel, d’automatiser certaines tâches ou d’explorer les données de manière guidée. Par exemple, Joule peut expliquer une variation d’indicateur, générer une prévision ou même déclencher des alertes automatiques en langage simple. Ces agents intelligents intégrés sont un différenciateur clé de SAP BDC : l’IA est mise au service de l’utilisateur métier de façon prête à l’emploi. Enfin, SAP BDC bénéficie des capacités de Databricks intégrées pour tout ce qui est data science avancée et AI/ML : les data scientists peuvent exploiter des notebooks, Spark et les bibliothèques machine learning au sein même de la plateforme, tout en restant connectés aux données business (via le business context SAP). En somme, pour les besoins analytiques orientés métiers SAP, BDC fournit un ensemble cohérent : des tableaux de bord packagés aux insight apps sectorielles, de la planification intégrée, et des agents AI (Joule) pour automatiser et guider l’analyse au quotidien.
Microsoft Fabric : Power BI et la puissance analytique polyvalente. Microsoft Fabric s’appuie principalement sur Power BI pour la couche BI et visualisation. Power BI est un des leaders du marché de la BI depuis plusieurs années (Leader du Magic Quadrant Gartner BI en 2023), apprécié pour sa richesse fonctionnelle et sa facilité d’utilisation par les analystes. Intégré nativement dans Fabric, Power BI permet de construire des rapports interactifs, des tableaux de bord dynamiques et même des analyses en langage naturel (Q&A) pour interroger les données. Les utilisateurs métier bénéficient de toutes les fonctionnalités avancées de Power BI (analyses assistées par l’IA, alertes, export vers Excel, partage via Teams). Là où Fabric va plus loin, c’est dans la palette complète d’analytique mise à disposition : au-delà de la BI, Fabric inclut des modules pour la data science (Synapse Data Science, avec notebooks Jupyter/Spark pour créer des modèles ML) et pour l’analytique temps réel. Ainsi, sur une même plateforme, on peut à la fois créer un modèle de machine learning sur les données du lac, l’exposer via un pipeline, et en visualiser les résultats instantanément dans Power BI. Pour l’IA chez MS Fabric, nous aurons l’incoutable MS Copilot à disposition dans l’ensemble des expériences.
Scénarios métiers : quand utiliser l’une ou l’autre, ou les deux ?
Après avoir vu les caractéristiques, comment choisir la bonne approche pour un cas d’usage métier ? En réalité, Microsoft Fabric et SAP BDC ne s’excluent pas mutuellement : chacune peut exceller dans certains scénarios. Voici quelques situations concrètes illustrant leur utilisation différenciée – et parfois complémentaire.
Entreprise 100% SAP (scénario “SAP-centric”) : Pour une organisation dont la majorité des processus et données sont gérés par des solutions SAP (ERP, CRM, Supply Chain, etc.), SAP Business Data Cloud apparaît comme un choix naturel. Par exemple, une entreprise industrielle utilisant SAP pour la production, les stocks et la finance pourra avec BDC consolider toutes ces données dans un modèle unifié, et utiliser les insight apps fournies pour analyser sa chaîne logistique de bout en bout. La planification financière intégrée dans SAC permettra de faire du budget et du prévisionnel directement à partir des données réelles SAP. Dans ce contexte, Microsoft Fabric pourrait sembler moins nécessaire. Cependant, même dans un paysage très SAP, Fabric peut avoir sa place pour des besoins spécifiques : si cette entreprise souhaite croiser ses données SAP avec des données externes (par ex. des données de marché, des données météo influant sur les ventes, etc.), elle pourrait brancher Fabric en complément. Par exemple, les données SAP de production restent dans BDC pour le suivi interne, mais sont également extraites vers Fabric afin d’être combinées à des données IoT de capteurs machines, et analysées via un modèle IA dans Fabric. On le voit, dans un scénario SAP-centric, BDC serait l’outil principal pour tout ce qui est reporting standard et pilotage opérationnel sur SAP, tandis que Fabric servirait d’accélérateur ponctuel pour des analyses innovantes impliquant d’autres sources ou technologies.
Organisation hybride (scénario “SI mixte”) : Prenons le cas d’une société de distribution dont le SI est réparti entre plusieurs technologies : un ERP SAP pour la gestion des achats et stocks, mais un CRM Salesforce pour la relation client, et des bases de données spécifiques pour la logistique entrepôt, etc. Dans ce contexte hétérogène, le défi est d’unifier la donnée pour avoir une vision 360° du business. Microsoft Fabric pourrait jouer le rôle de plateforme transversale : en connectant aussi bien SAP, Salesforce que les bases internes, Fabric permet de tout charger dans OneLake et de bâtir un data warehouse global. Les équipes data pourraient alors développer des tableaux de bord Power BI montrant, par exemple, la performance commerciale en combinant les données de commandes SAP et les opportunités du CRM non-SAP. Néanmoins, l’entreprise pourrait aussi tirer parti de SAP BDC en parallèle. En effet, certaines analyses pointues liées aux processus SAP (par ex. l’analyse des écarts d’inventaire ou l’optimisation des niveaux de stock) pourraient être réalisées plus rapidement dans BDC en utilisant le contenu pré-packagé SAP. Pendant que Fabric agrège les données pour une analytique plus large, BDC assurerait la cohérence métier et la validation des chiffres côté SAP. Les deux plateformes partageraient éventuellement des données de référence : on peut imaginer exporter les résultats d’une prédiction faite dans Fabric vers SAP BDC pour qu’ils soient intégrés dans un dashboard SAC, ou à l’inverse exposer un data model SAP BDC via un connecteur ODBC/OData pour qu’il soit repris dans Power BI. Ce scénario montre bien une cohabitation où chaque solution est utilisée selon ses forces : Fabric pour l’interopérabilité et la consolidation multi-source, SAP BDC pour la valeur métier immédiate sur les données SAP.
Focus sur l’innovation IA : Dans un cas où une entreprise cherche avant tout à développer des cas d’usage avancés d’IA et machine learning (par ex. maintenance prédictive, segmentation client fine, moteur de recommandation produit), Microsoft Fabric offre un bac à sable idéal. Grâce à son intégration de Synapse Spark et de l’IA Azure, les data scientists peuvent itérer rapidement en exploitant des données variées. Imaginons une start-up ou un service R&D qui doit tester des modèles sur des données venant de systèmes SAP + d’autres sources open data : Fabric leur permettra de casser les silos et d’unifier ces datasets pour entraîner des modèles, le tout sans gérer d’infrastructure. SAP BDC, dans ce cas, pourrait ne servir que de source de données (en exposant les données SAP pertinentes) ou de point d’atterrissage des résultats pour les réinjecter dans les processus métier SAP. Par exemple, les scores d’un modèle d’attrition client calculés dans Fabric pourraient être renvoyés vers SAP BDC (via un partage Delta ou une API) afin d’être intégrés dans la vue client globale dans SAC. Ainsi, pour les projets très orientés Data Science/IA cross-domain, Fabric serait l’outil principal, et SAP BDC assurerait l’alignement au métier en récupérant les insights pour les rendre actionnables par les équipes métier SAP.
En résumé, le choix dépendra fortement du contexte de l’entreprise : si vos besoins sont centrés sur l’analyse de vos données SAP avec un maximum de contexte métier et des solutions packagées, SAP BDC est taillé pour ça. Si au contraire vos données sont éparses et que vous recherchez une plateforme générale pour tout unifier et innover (ou déjà bien ancrée Microsoft), Fabric sera un excellent candidat. Et dans beaucoup de cas, une approche combinée est non seulement possible mais souhaitable, pour tirer le meilleur des deux mondes.
Interopérabilité et cohabitation : adversaires ou alliés ?
Bien que Microsoft Fabric et SAP Business Data Cloud soient souvent présentés en opposition (Microsoft vs SAP), la frontière n’est pas étanche. Grâce aux standards ouverts et à des efforts des deux éditeurs, interopérer les deux solutions est envisageable.
Côté SAP BDC, l’ouverture passe notamment par l’adoption de technologies standard de l’écosystème data. Par exemple, SAP BDC utilise un format de lakehouse basé sur Delta Lake (via Databricks) pour stocker ses données dans l’object store. SAP a annoncé la possibilité prochaine de consommer les data products de BDC via Delta Sharing – un protocole ouvert largement supporté, ce qui signifie que des outils externes (comme justement Power BI, Python, etc.) pourront accéder aux données de BDC de manière sécurisée sans extraction complexe. De même, les API et connecteurs OData de SAP restent utilisables pour interroger les données depuis l’extérieur.
Côté Microsoft Fabric, l’ouverture est également un principe de base : OneLake supporte nativement les formats Parquet, Delta et peut même se connecter à des données sur AWS ou Google Cloud. Fabric est donc multi-cloud et “open lakehouse” par conception. Un modèle de données créé dans Fabric (par ex. un dataset Power BI ou une table lakehouse) peut être exposé via une API Rest, ou connectable via un pilote SQL standard (ODBC/JDBC) – ce qui ouvre la porte à sa consommation par des outils tiers, y compris potentiellement par SAP Analytics Cloud ou Datasphere si l’entreprise le souhaite. Microsoft travaille par ailleurs en partenariat avec SAP sur des connecteurs et solutions d’intégration. Des guides et outils existent pour intégrer des données SAP dans Azure (et donc Fabric) facilement. L’alliance SAP–Microsoft n’est pas nouvelle (programme Embrace pour déployer SAP sur Azure, connectivité entre Azure AI et SAP, etc.), et on peut s’attendre à ce que cette interopérabilité s’améliore continuellement.
En pratique, si vous souhaitez faire cohabiter SAP BDC et Microsoft Fabric, il est tout à fait possible de le faire via des mécanismes d’échange de données maîtrisés : connecteurs natifs, API, fichiers partagés, ou encore l’utilisation de zones neutres (data lake commun). L’important est de définir quelle plateforme joue quel rôle dans votre architecture : par exemple, SAP BDC peut être la “source de vérité” pour les données maîtres et indicateurs SAP, tandis que Fabric sert de bac d’exploration et d’enrichissement avec d’autres données. Ou inversement, Fabric centralise tout le raw data (données brutes) tandis que BDC se connecte à Fabric pour lire certaines données externes lorsqu’un besoin métier SAP l’impose. Les deux approches se valent, du moment que les responsabilités sont claires (éviter les doublons et les divergences de chiffres).
En définitive, Microsoft Fabric et SAP BDC peuvent être vus comme des alliés dans la quête d’une décision basée sur les données. Leur interopérabilité, bien que naissante, va probablement se renforcer (via des standards ouverts comme Delta Sharing, des partenariats cloud, etc.). Plutôt que d’y voir un duel frontal, il est souvent plus fructueux de les considérer comme deux briques complémentaires d’un écosystème data moderne, surtout pour les grandes organisations multi-logiciels.
Coûts et modèles économiques : à évaluer selon votre contexte
Un mot sur les coûts et le modèle de licensing, qui peut influencer le choix entre Fabric et BDC (ou la combinaison des deux). Les deux solutions étant des offres cloud managées (SaaS), on échappe aux coûts d’infrastructure classique, mais on adopte un modèle d’abonnement ou de consommation.
SAP BDC : SAP n’a pas encore détaillé publiquement tout le modèle de tarification de Business Data Cloud (lancé en 2025, la première moitié de l’année sert à préciser l’offre). Néanmoins, on sait que BDC remplace des produits existants comme SAC et Datasphere qui avaient leurs propres licences. Il est probable que SAP propose un forfait englobant une certaine capacité de stockage (notamment sur l’object store) et des utilisateurs SAC, avec des options en fonction des composants utilisés (par ex. activer l’option BW/4HANA PCE pourrait être un extra). L’intégration de Databricks dans BDC suggère aussi un modèle de facturation soit inclus, soit en sus pour la partie compute big data. Un des objectifs affichés de SAP BDC est de réduire le TCO (coût total) par rapport aux solutions purement on-premise ou full HANA en exploitant du stockage moins coûteux : par exemple, stocker des données chaudes dans l’objet store plutôt qu’en mémoire HANA revient bien moins cher et permet de gérer de gros volumes à coût raisonnable. Pour les clients SAP déjà engagés, BDC pourra représenter une optimisation financière en évitant d’acheter séparément un data warehouse tiers ou des outils de BI additionnels – tout en prolongeant la valeur de leurs investissements SAP (par ex. réutiliser des modèles BW existants dans le cloud via BDC au lieu de repartir de zéro).
Microsoft Fabric : Du côté de Microsoft, Fabric est actuellement inclus (en préversion) pour les clients Power BI Premium sans surcoût. À terme, le modèle s’aligne sur celui de Power BI Premium ou d’Azure : c’est-à-dire une facturation à la capacité (par nœud de calcul alloué, par heure) ou à la consommation de ressources. Microsoft a communiqué sur des unités de capacité F2/F4/F8 etc., avec un tarif horaire qui inclut l’usage de tous les services Fabric correspondants. Cela signifie que le client n’a pas à payer séparément pour chaque composant (ETL, base, BI…) : un certain niveau de capacité Fabric donne droit à utiliser l’ensemble, jusqu’à la limite de cette capacité. Ce modèle flexible et échelonnable convient bien, par exemple, à un démarrage modeste (on peut commencer avec une petite capacité pour un projet pilote, puis augmenter en fonction de l’adoption). Pour une entreprise déjà équipée largement en licences Microsoft 365/Power BI, l’ajout de Fabric peut être très compétitif par rapport à l’achat d’une solution séparée côté SAP, car il s’inscrit dans la continuité des contrats existants. En revanche, pour une entreprise pleinement SAP qui n’a pas ou peu d’infrastructure Azure, il faut prendre en compte le coût d’entrée dans l’écosystème Microsoft (formation, éventuellement services Azure additionnels comme Azure AD si pas utilisés, etc.).
En résumé, difficile de déclarer un gagnant côté coûts : cela dépend de votre point de départ (effet de synergie avec vos licences existantes), de l’ampleur des données à traiter et du nombre d’utilisateurs. Dans tous les cas, il conviendra d’évaluer précisément les besoins : par exemple, si vous n’avez besoin que de reporting sur données SAP pour quelques contrôleurs de gestion, la proposition de SAP BDC (incluant SAC) sera calibrée; à l’inverse si vous avez des data scientists, des analystes marketing et des dizaines de sources différentes, l’investissement dans Fabric sera rapidement rentabilisé. Une approche pragmatique consiste aussi à expérimenter (les deux solutions offrant des périodes d’essai ou des étapes pilotes) afin de modéliser le coût en fonction de vos usages réels.
Expérience utilisateur et déploiement : à qui s’adressent ces plateformes ?
Le succès d’une solution analytics dépend aussi de son adoption par les utilisateurs – qu’ils soient IT, data analysts ou directement utilisateurs métier. Là encore, Microsoft Fabric et SAP BDC offrent des expériences un peu différentes, reflétant leur orientation.
SAP BDC : pensé pour les “utilisateurs SAP”. SAP Business Data Cloud va sembler familier à ceux qui connaissent déjà les outils SAP. L’interface reprend en grande partie les éléments de SAP Analytics Cloud (pour la partie BI/planification) et de Datasphere (pour la partie modélisation de données), le tout pouvant être orchestré via un portail unique SAP. Un utilisateur métier SAP (par ex. un contrôleur, un analyste RH) retrouvera un environnement cohérent avec ce qu’il a en production, et pourra naviguer à travers des contenus déjà préparés par SAP ou par l’IT interne. L’expérience est assez guidée et pédagogique : SAP propose des stories (rapports interactifs) prêts à l’emploi et l’assistant Joule peut accompagner l’utilisateur dans ses questions. Pour les profils plus techniques (data engineer, BI), BDC offre également un cadre intégré mais attend de ces utilisateurs qu’ils aient une certaine connaissance de l’écosystème SAP (modèles ABAP CDS, notions de BW ou HANA, etc., selon les cas). En termes de déploiement, BDC étant un SaaS managé par SAP, la mise en route est relativement simple pour l’administrateur : on souscrit au service et SAP se charge de l’infrastructure. Toutefois, il faut prévoir un effort de configuration initial pour brancher les sources (connecter les systèmes SAP on-premise via des agents cloud, définir les espaces de travail, etc.) et pour adapter les data products SAP aux spécificités de l’entreprise. Globalement, l’expérience utilisateur de BDC est très appréciée dans un contexte où l’on veut rapidement délivrer du contenu métier sans trop de développements libres – c’est en cela une continuité de la philosophie SAP BW (pré-packagé) modernisée avec le cloud.
Microsoft Fabric : conçu pour la polyvalence et la collaboration. L’expérience Microsoft Fabric, quant à elle, se distingue par sa polyvalence et sa proximité avec les outils collaboratifs courants. Les utilisateurs de Power BI ne seront pas dépaysés, puisque l’interface de Fabric est intégrée à celle du service Power BI en ligne. On y gère des workspaces (espaces de travail) où cohabitent dashboards Power BI, pipelines de données, notebooks, etc. Un analyste métier pourra principalement interagir via les applications Power BI (web ou desktop) pour consommer ou créer des rapports. Un data engineer ou data scientist aura accès à des environnements familiers comme des notebooks Jupyter, du SQL, du Spark, directement dans le portail Fabric ou via des outils comme VS Code. Cette diversité des expériences est un point fort de Fabric : chaque rôle utilise l’interface ou l’outil qui lui convient le mieux, mais tous partagent le même espace unifié de données en arrière-plan. La collaboration est aussi facilitée par l’intégration M365 : commenter un rapport via Teams, co-éditer un pipeline de données, partager un lien OneLake… tout cela suit l’ergonomie bien connue des applications Microsoft. En contrepartie, Fabric demande peut-être un peu plus de “bricolage” initial pour créer les solutions analytiques : là où SAP fournit des modèles prédéfinis, Fabric vous donne la boîte à outils et c’est à vos équipes de concevoir les modèles de données, les mesures DAX dans Power BI, etc. Cela offre plus de liberté et de personnalisation, au prix d’un investissement en temps/hommes plus important pour arriver au même résultat final. En termes de déploiement, Fabric est aussi un SaaS – l’activation est quasi-instantanée (souvent juste activer dans l’administration Power BI)– mais la prise en main par toutes les parties prenantes peut nécessiter une conduite du changement (former les équipes data à Synapse s’ils ne connaissent pas, par exemple). Au final, l’expérience Fabric est très appréciée dans les environnements où l’on valorise la collaboration agile entre IT et métiers, et où l’on veut outiller différents profils autour d’un langage commun de la data (même plateforme mais multiples interfaces adaptées à chacun).
Tableau comparatif des points clés
Conclusion : complémentarité au service des métiers, au-delà du « buzz »
En conclusion, Microsoft Fabric et SAP Business Data Cloud apportent chacun des réponses solides aux défis de l’analytics moderne, avec des angles différents. Plutôt que de chercher à couronner un vainqueur, il est plus utile de comprendre comment tirer parti de l’un et de l’autre en fonction de votre environnement.
SAP BDC représente le prolongement naturel de l’univers SAP vers le cloud data et l’IA, en capitalisant sur la connaissance métier accumulée dans vos systèmes. Il brille pour fournir rapidement des solutions prêtes à l’emploi aux utilisateurs métier dans un langage qu’ils comprennent, surtout si votre SI est déjà très centré sur SAP.
Microsoft Fabric incarne une approche transversale et ouverte, idéale pour bâtir un hub analytique global. Il excelle dès qu’il s’agit de fédérer de multiples sources et de donner aux équipes data les moyens d’innover sans contraintes, tout en diffusant la culture data via les outils collaboratifs connus de tous.
Dans de nombreux cas, les deux mondes ne sont pas incompatibles : on peut très bien imaginer un paysage data où SAP BDC gère les rapports financiers officiels pendant que Fabric sert aux analyses exploratoires, ou où Fabric intègre toutes les données brutes pendant que SAP BDC fournit aux contrôleurs un cockpit de pilotage consolidé. L’important est de garder une vision centrée sur le métier : quelles décisions devez-vous éclairer ? quels utilisateurs doivent être autonomes ? La réponse à ces questions vous guidera pour assembler le meilleur mix technologique.
En clair, évitons le buzz et les positions tranchées : voici les faits – SAP BDC et Microsoft Fabric ont chacun leurs points forts. Le véritable enjeu est de savoir comment les combiner intelligemment pour créer de la valeur métier à partir de vos données, sans se perdre dans la complexité. Avec une approche pragmatique, ces deux plateformes peuvent devenir complémentaires et non concurrentes, au bénéfice d’une analytique d’entreprise plus performante et accessible à tous.
🔵 Sources Microsoft Fabric
Microsoft Learn / Documentation officielle Fabric 📚 https://learn.microsoft.com/fabric ➤ Utilisé pour comprendre l’architecture de Fabric, ses composants (OneLake, Data Factory, Synapse, Power BI), sa gouvernance (Purview), et son modèle de capacité.
Blog officiel Microsoft – Introducing Microsoft Fabric ✍️ Arun Ulag (Corporate VP, Power BI) 📅 Mai 2023 📚 https://powerbi.microsoft.com/blog/introducing-microsoft-fabric/ ➤ Pour les annonces clés, la vision « unifiée », l’intégration avec Power BI et les cas d’usage métiers.
Microsoft Ignite 2023 Sessions & Keynotes 📺 Disponible via https://ignite.microsoft.com ➤ Détails sur Copilot, l’intégration Fabric + M365, les modules IA et temps réel.
Articles et posts communautaires – Nadim Abou-Khalil (MVP Data Platform) 📅 2023-2024 ➤ Pour ses posts détaillés sur les différences Fabric / BDC, la gouvernance, la puissance de Power BI, la stratégie de Microsoft. (Ex. sur LinkedIn)
🟢 Sources SAP Business Data Cloud (BDC)
SAP Newsroom – Annonce officielle de SAP Business Data Cloud 📅 Mars 2024 📚 https://news.sap.com ➤ Présentation de SAP BDC, ses composants, l’objectif d’unification Datasphere + SAC + Databricks.
Documentation SAP Datasphere + SAP Analytics Cloud 📚 https://help.sap.com ➤ Détails techniques sur la modélisation, les data products, la gouvernance, l’intégration Databricks.
Webinar SAP & Databricks – How SAP BDC Uses Open Lakehouse 🎥 Webinaire disponible sur SAP Events ➤ Pour la partie Delta Lake / Delta Sharing / extension via Databricks.
Partenaires SAP (Collibra, Confluent, Databricks) 🔗 Informations sur les intégrations natives avec les écosystèmes de gouvernance, streaming et big data.
Blog BARC (Business Application Research Center) 📄 SAP Business Data Cloud: What You Need to Know ➤ Analyse indépendante sur les promesses de SAP BDC, ses différences avec Datasphere ou BW/4HANA.
🟣 Sources croisées et comparatives / Interopérabilité
Blog Deloitte – SAP BDC & Fabric, Future of Data Architecture ➤ Vision d’architecture data hybride avec BDC + Fabric, cas d’usage réels (industrie, pharma…).
LinkedIn / Blog personnel de consultants SAP & Microsoft ✍️ Experts comme Nicolas Raspal, Xavier Morcillo, ou Bastien Fenioux ➤ Retours terrain sur les usages combinés SAP + Microsoft.
Documentation Delta Sharing (Databricks) 📚 https://databricks.com/open-source/delta-sharing ➤ Utilisée pour expliquer la possibilité d’exporter des données SAP BDC vers Power BI/Fabric via protocole ouvert.
Microsoft continue d’enrichir son écosystème data avec AI Skills, une fonctionnalité qui permet d’interroger ses données en langage naturel. Plus besoin de SQL, T-SQL ou KQL, il suffit de poser une question et l’IA retourne directement la réponse, sous forme de tableau, de graphe ou de texte.
L’idée est simple : rendre l’analyse des données accessible à tous, sans barrière technique.
Mais comment ça fonctionne réellement ? Quels sont les avantages et les limites ? Et surtout, est-ce que cela signifie la fin des requêtes SQL dans Power BI et Fabric ?
AI Skills, c’est quoi exactement ?
Contrairement à Copilot qui assiste dans la création de rapports et l’écriture de formules, AI Skills est un véritable agent conversationnel, conçu sur mesure et entraîné sur vos propres données.
Son objectif : vous permettre d’interroger une base de données aussi facilement que vous poseriez une question sur Google.
Concrètement, on peut lui demander :
Quels sont mes produits les plus vendus en janvier ?
Quels clients ont passé plus de trois commandes ce trimestre ?
Quelle est l’évolution des ventes sur six mois en Europe ?
L’IA génère automatiquement la requête, interroge la base et affiche la réponse.
AI Skills vs Copilot : quelles différences ?
Microsoft propose plusieurs outils basés sur l’IA, et il est essentiel de bien les différencier.
Fonctionnalité
Copilot Power BI
AI Skills Microsoft Fabric
Objectif
Assister dans la création de rapports et formules (DAX, SQL)
Interroger des bases de données en langage naturel
Données utilisées
Un modèle IA généraliste
Vos propres données
Interaction
Génération de DAX, explication d’insights
Réponses directes à des questions spécifiques
Personnalisation
Limitée
Fortement adaptable
Utilisateurs cibles
Analystes Power BI ou autres
Métiers sans compétences techniques
Copilot est un assistant pour les analystes et développeurs BI qui les aide à mieux exploiter Power BI. AI Skills est conçu pour les utilisateurs métier, leur permettant d’exploiter leurs données sans passer par un analyste.
Comment ça fonctionne ?
L’implémentation d’AI Skills dans Microsoft Fabric repose sur la création d’un agent conversationnel qui s’entraîne à comprendre les données disponibles.
Mise en place d’AI Skills :
Créer un agent dans Microsoft Fabric.
Définir les sources de données (Warehouse, Lakehouse, etc.).
Fournir des exemples de questions-réponses pour améliorer la compréhension du modèle.
Intégrer l’agent à Power BI, Teams ou un chatbot.
L’objectif est d’obtenir une IA capable de comprendre le vocabulaire métier, d’interpréter les demandes et de répondre avec des données précises.
Les avantages d’AI Skills
L’intérêt principal est de démocratiser l’accès aux données en supprimant la nécessité d’écrire des requêtes complexes.
Gain de temps : plus besoin d’écrire des requêtes SQL ou de naviguer dans des dashboards.
Accessibilité : permet aux non-techniques d’exploiter les données.
Automatisation : réduit la charge de travail des analystes et facilite l’exploration des données.
Amélioration continue : l’agent s’adapte et devient plus performant avec le temps.
Microsoft propose une approche où l’IA n’est plus seulement un outil, mais un véritable collaborateur dans l’analyse des données.
Limites et points de vigilance
Si AI Skills apporte une réelle avancée, il y a encore des défis à relever :
Dépendance à la qualité des données : une IA mal entraînée ou une base mal structurée peut générer des réponses erronées.
Nécessité d’un paramétrage précis : l’agent doit être bien configuré pour éviter des interprétations hasardeuses.
Pas une solution miracle : pour les requêtes complexes, une intervention humaine reste indispensable.
AI Skills ne remplace pas les analystes, mais leur offre un gain de productivité considérable en automatisant certaines tâches répétitives.
Conclusion : une avancée majeure, mais pas la fin du SQL
AI Skills est une évolution logique vers une BI plus accessible et interactive. Il permet aux utilisateurs métier de poser des questions directement à leurs bases de données, sans intermédiaire.
Pour les analystes, c’est un excellent complément, qui libère du temps pour des tâches plus complexes.
Microsoft ne tue pas SQL, mais ouvre une nouvelle ère dans l’exploitation des données.
Reste à voir comment cette technologie évoluera et si elle s’imposera comme un standard incontournable dans les entreprises.
Microsoft force la migration de Power BI Premium vers Fabric Capacity… et heureusement, un outil est là pour ça !
C’était écrit : les licences Power BI Premium par capacité (P-SKUs) vont disparaître au profit des capacités Fabric (F-SKUs). Dès février 2025, plus de renouvellement possible pour une P-SKU, il faudra passer sur Fabric.
Microsoft Fabric, c’est Power BI Premium + tout un écosystème data moderne (Data Warehouse, Real-Time Analytics, Notebooks, etc.). Mais la vraie question, c’est comment migrer proprement sans perdre en organisation et en efficacité ?
Microsoft a prévu un outil pour migrer les workspaces en masse
Bonne nouvelle : ça évite une migration manuelle, workspace par workspace. Mauvaise nouvelle : il faut bien anticiper, car tout ne se migre pas aussi facilement qu’on aimerait.
Dans cet article, on va voir :
Pourquoi cette transition et ce qui change avec Fabric
Comment utiliser l’outil de migration pour gagner du temps
Les pièges à éviter pour éviter les mauvaises surprises
Pourquoi Power BI Premium disparaît au profit de Fabric ?
À partir du 1er février 2025 :
Plus de renouvellement possible pour une P-SKU, il faudra passer sur une capacité Fabric
Power BI Premium reste le même, mais devient une partie intégrante de Microsoft Fabric
Nouveau modèle économique : abonnement à l’usage (pay-as-you-go) ou engagement (jusqu’à 40,5 % d’économies)
Accès aux fonctionnalités exclusives Azure, comme les Managed Private Endpoints
L’outil de migration automatique : indispensable pour les gros tenants
Semantic Link Lab : la brique centrale du processus
L’outil de migration repose sur Semantic Link Lab, une bibliothèque de fonctions permettant de gérer en masse les objets Fabric et Power BI. C’est une boîte à outils open-source qui facilite l’automatisation de nombreuses tâches : ✅ Migration des workspaces Power BI vers Fabric Capacity ✅ Migration des modèles Import/DirectQuery vers DirectLake ✅ Analyse des bonnes pratiques des modèles sémantiques (Best Practice Analyzer) ✅ Vérification des performances des modèles avec VertiPaq Analyzer ✅ Plus de 300 fonctions pour gérer les objets Fabric et Power BI
En bref, Microsoft s’appuie sur cet outil puissant pour industrialiser la migration des workspaces.
Comment fonctionne l’outil de migration ?
Microsoft a mis en place un outil de migration basé sur les API REST Fabric, qui permet de : ✅ Créer automatiquement des capacités Fabric en mode pay-as-you-go ✅ Réassigner tous vos workspaces sans passer par une migration manuelle ✅ Garder les mêmes paramètres d’administration et de région ✅ Migrer plusieurs capacités en même temps
Ce que l’outil ne fait pas automatiquement
⚠️ Les paramètres avancés de la capacité (disaster recovery, notifications…) ⚠️ Les workspaces contenant des artefacts Fabric ne peuvent pas être déplacés dans une autre région ⚠️ Les modèles sémantiques volumineux doivent rester dans leur région d’origine ⚠️ Désactiver Fabric pour accélérer la migration peut poser problème si certains éléments critiques sont supprimés
Bon à savoir : Vous avez 90 jours après l’expiration de votre P-SKU pour récupérer vos données et migrer proprement.
Comment bien utiliser l’outil de migration ?
1️⃣ Vérifier les workspaces concernés
Quels workspaces doivent être migrés ?
Contiennent-ils des artefacts Fabric (Data Warehouse, Notebooks, Pipelines) ?
Sont-ils bien localisés dans la même région ?
2️⃣ Préparer les capacités Fabric F-SKU
Si elles sont déjà créées, l’outil les utilisera directement
Si elles ne le sont pas, l’outil pourra les générer automatiquement en mode pay-as-you-go
3️⃣ Lancer l’outil et migrer les workspaces
Utiliser le notebook Microsoft pour assigner les workspaces automatiquement
4️⃣ Reconfigurer les paramètres avancés
Les paramètres spécifiques ne sont pas migrés automatiquement et doivent être reparamétrés à la main
5️⃣ Tester et valider la migration
Vérifier que tous les workspaces sont bien assignés
Supprimer les anciennes capacités P-SKU une fois la transition finalisée
Faut-il migrer tout de suite ?
Jusqu’à février 2025, vous pouvez continuer d’utiliser vos P-SKUs. Mais dès votre prochain renouvellement, vous serez obligés de passer sur Fabric Capacity.
Si vous ne migrez pas dans les 90 jours après expiration de votre P-SKU, vos workspaces seront rétrogradés en Power BI Pro.
Si vous avez un grand nombre de workspaces, mieux vaut anticiper et tester la migration en avance.
Pourquoi Microsoft pousse cette transition ?
Microsoft veut unifier son offre et faire de Fabric la norme :
Fabric est un “Power BI Premium++”, avec une plateforme data complète
Les capacités Fabric permettent une meilleure scalabilité et plus de flexibilité économique
Fabric permet d’accéder à des fonctionnalités Azure avancées
En clair, ce n’est pas juste un changement de licence, c’est un vrai tournant stratégique.
Conclusion : Anticipez votre migration dès maintenant !
Si vous êtes déjà dans une logique Fabric, cette migration ne changera pas grand-chose. Mais si vous êtes resté sur un modèle Power BI Premium classique, il faut s’organiser dès maintenant.
Mon conseil : testez l’outil de migration et préparez vos nouvelles capacités Fabric dès aujourd’hui.